

There’s a quiet revolution underway in the C-suite! About 80% of CEOs have already implemented or are planning to implement conversational AI to transform customer engagement. Customers now demand quick answers to their questions. Businesses can match expectations and make the interaction more personalized by using conversational AI
Conversational AI holds great promise across a wide range of sectors, including retail, healthcare, and finance. This is evident from the explosive expansion of the conversational AI market, which is expected to reach $49.9 billion by 2030, up from $13.2 billion in 2024. These figures aren’t just numbers; they’re a wake-up call to businesses to change or risk being left behind.
With generative AI on the horizon, the future looks promising as these conversations will become more human-like. By 2026, GenAI is set to be included in 80% of conversational AI products, enabling richer and more complex interactions.
As an organization, we have developed quite a few conversational AI products for startups and big techs. Our insights will help you understand what conversational AI is and what it holds in store for us better. We will go step-by-step; first we will break down this technology, then look at its use cases, and finally, describe the process of implementing conversational AI.
What is conversational AI?
Conversational AI is an intelligent program that mimics real-world conversations using digital and telecommunications technologies to provide a superior conversational experience. It is a complex interplay of technologies where each contributes uniquely to the creation of sophisticated conversational systems.
Key components of conversational AI
Conversational AI brings together eight technology components.
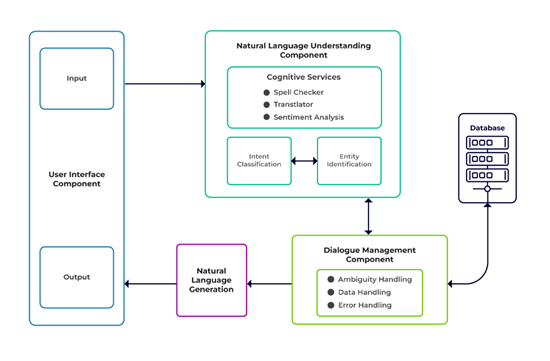
Natural Language Understanding (NLU): NLU interprets user input, discern intent and extract relevant information for accurate and contextually relevant responses personalized interactions.
Dialog Management: It serves as the conversational AI’s conductor and orchestrates the conversation flow. Dialog Management leverages insights from NLU to make responses more coherent and valid by maintaining the chatbot’s conversational context and logic.
Natural Language Generation (NLG): NLG transforms structured data into natural, fluent language. It crafts coherent, context-sensitive, engaging, intuitively connected, and human-like responses to enhance the user’s conversational experience.
Database/ Content Management System: A Database or CMS stores key information and histories, enabling the chatbot to deliver accurate, personalized responses, enhancing relevance and user impact.
User Interface (UI): Users interact with the chatbot via UI. A simple and easy-to-use UI facilitates seamless communication between user and the conversational AI.
Integration Layer: The integration layer acts as a bridge between the chatbot and external systems and data sources to facilitate access to a variety of features, complete difficult tasks and providing real-time responses.
Machine Learning and Analytics: Machine Learning and Analytics constantly analyze interactions to refine and enhance the chatbot’s performance. It also optimizes the chatbot’s learning curve and provides valuable insights into user behavior and preferences to enhance conversational experience.
How does conversational AI work?
Conversational AI uses a series of interrelated procedures to replicate human-like interactions. Its foundation is based on natural language processing (NLP), which understands and generates human language, enabling dynamic and responsive communication.
Let’s look at a real-world scenario with a consumer named Sarah. She visits an online retail platform for an order status update and opens the conversational AI-powered chatbot to ask, “What’s the status of my order?” instead of waiting for a human representative.
The NLU component interprets her request to understand her intent (the status of her purchase) and then extracts relevant information from the conversation or the user’s profile, such as her identity and order number.
Based on this information, the dialog management system establishes the flow of the conversation. It preserves context, ensuring that Sarah maintains a coherent conversation. If Sarah asks, “Can I change the delivery address?”, the system effortlessly adapts to accommodate her new request.
The content management system or database retrieves essential information about Sarah’s order, such as its current status and the possibility of changing address information. This critical data retrieval serves as the basis for the AI’s responses.
After retrieving the necessary information, the NLG component creates a response that is both correct and engaging for the conversation. For example, it can say, “Your order is being processed and will be shipped within the next two days.” or “Do you want to change your delivery address?”.
Throughout the interaction, the UI displays information clearly, employing an intuitive layout to represent the flow of the conversation and allowing Sarah to quickly respond with alternatives such as selecting buttons to indicate her desire. If Sarah decides to change her delivery address, the integration layer connects the chatbot to the company’s order management system, allowing the AI to update records in real time.
After the interaction, the machine learning component analyzes the chat to find trends in user behavior, such as typical queries or difficulties, improving the AI’s understanding for
future customers. This ongoing analysis improves the entire customer experience and ensures that conversational AI can adapt to changing consumer expectations.
A step-by-step guide to conversational AI implementation
When implemented properly, conversational AI can help businesses scale and thrive in competitive environments. However, achieving this success demands meticulous planning and flawless execution.
1. Determining your conversational AI objectives
Determining your objectives for implementing conversational AI is a critical step. It requires a complete understanding of the user stories and business requirements. To find what you need exactly, begin by:
- Defining your objectives and use cases:
- Identify the end goal and business objectives.
- Articulate the specific business problem or opportunity.
- Define SMART goals aligned with your business objectives.
- Specific – what exactly are you trying to achieve? (e.g. reduce support wait times by 20%)
- Measurable – How will you track progress? (e.g. customer satisfaction survey)
- Achievable – Is your goal realistic within your resources and time frame?
- Relevant – Do your goals support your overall business goals?
- Time bound – when do you want to achieve this goal?
- Choose relevant KPIs to track progress and performance.
- Considering technical and operational needs:
- Assess NLP capabilities and integration requirements.
- Explore customization options and multichannel support.
- Evaluate analytics, reporting, scalability, security, and compliance.
- Prioritizing and Collaborating:
- Prioritize goals and KPIs based on importance and urgency.
- Communicate with stakeholders for feedback and align expectations.
- Regularly review and refine goals and KPIs.
By addressing these elements, you can establish a robust foundation for your conversational AI project, ensuring it aligns strategically with your business goals and delivers the desired outcomes.
2. Designing conversational flows
The conversational flow can either follow a happy path or a sad path. Understanding the technical capabilities of Conversational AI and the nuances of human conversation is the key. For a happy path, always choose a structured approach that can help you create engaging and efficient interactions between your Conversational AI and its users. Conversations that run in a loop often lead to unsatisfied customers.
- Understand your audience and define the chatbot persona:
- Research your target users’ preferences and needs.
- Design a chatbot persona that aligns with your brand and appeals to your target audience.
- Craft your Conversational UI elements:
- Keep conversations concise and engaging with emojis, rich content, and multimedia.
- Design for multiple channels to ensure a consistent user experience across platforms.
- Maintain transparency with users about the capabilities and limitations of the conversational AI.
- Develop and Refine Your Conversation Flow:
- Start by deciding your chatbot’s purpose and creating a conversation diagram.
- Write and test conversation scenarios to keep messages short and end conversations naturally.
- Use feedback to iterate and refine the conversation flow, ensuring it remains user-centric and flexible.
While planning your conversational flow, you should also consider how you are going to end the conversation. A short and curt reply or a ‘dry text’ is a conversation killer. For instance, ending a conversation with a simple ‘Bye’ sounds rude. Instead, you can ask the user, “Is there anything else I can do for you?”. Such a reply is always better to engage and impress the customer.
3. Integrating NLU (Natural Language Understanding) components
Integrating Natural Language Understanding (NLU) components into your Conversational AI solution is pivotal as it creates a system that can interpret and respond to user inputs accurately. Here’s how you can seamlessly incorporate NLU into your conversational AI:
- Initial Setup and Data Entry:
- Utilize a no-code studio environment for NLU management, requiring only a few training examples to start.
- Leverage a user-friendly graphical user interface (GUI) for entering NLU data, simplifying the process by eliminating the need to format data into JSON or CSV structures before importing.
- Consistency and Predictability:
- Ensure that when identical data is submitted, the NLU component produces consistent and predictable results with minimal to no variation, enhancing the reliability of your conversational AI.
- Optimization and Fine-Tuning:
- Engage in prompt design, engineering, and tuning to optimize the performance of Large Language Models (LLMs) alongside NLU.
- Incorporate Knowledge Bases with LLMs to ensure the highest possible accuracy and performance.
- Fine-tune LLMs by re-training them on a smaller, targeted dataset specific to your application’s needs, adjusting the model’s weights accordingly.
NLU’s primary job is to map words to actions, using dialogue to resolve any ambiguity. While NLUs can understand semantic patterns from unstructured data, developing chatbots requires extra caution. A single word can have multiple meanings—Paris, for example, could refer to a city or a person’s name. By meticulously addressing these uncertainties, you can make your bot more user-friendly.
4. Testing and iterating
Testing and iterating your Conversational AI, such as a virtual assistant for a food delivery app, involves a series of steps to ensure its efficiency and user satisfaction.
- Testing Types:
- Manual Testing: Engage real users or QA professionals to interact with the AI, simulating real-world use cases.
- Automated Testing: Utilize tools to simulate interactions, checking for response accuracy and system endurance under varied conditions.
- A/B Testing: Compare different versions of conversation flows or responses to determine which performs better in terms of user engagement and satisfaction.
- Key Testing Areas:
- Functional Testing: Assess the core functionalities, including user experience, NLU, and error handling
- Usability Testing: Evaluate the ease of interaction, focusing on the conversational UI elements and user engagement.
- Performance Testing: Measure response accuracy and times, throughput, fallback capabilities, personality alignment, ease of navigation, fallback capabilities, device compatibility, scalability and other performance metrics under different loads.
- Security Testing: Ensure data privacy and security of the AI model and system configurations.
- Iteration and Feedback:
- Continuous Monitoring: Track and analyze performance to identify any degradation or areas for improvement.
- Feedback Loops: Implement mechanisms to collect user feedback and downstream behavior to refine the conversational flows and responses.
- Re-training and Fine-tuning: Based on feedback and testing outcomes, adjust the NLU models and conversation scenarios to enhance accuracy and user experience.
Successful execution of these steps will make your app robust and keep users satisfied.
It’s also crucial to be vigilant about data bias. Recent studies have highlighted how underlying prejudices in data can influence algorithms, leading to discrimination and significant social consequences. For example, Amazon faced the threat of data bias in its recruitment system, which favored men due to flawed parameters in its hiring algorithm.
5. Deploying and monitoring your conversational AI
Deploying and monitoring your conversational AI demands continuous oversight to ensure optimal performance and user satisfaction.
Deployment steps:
- Cross-departmental collaboration: Ensure that teams across security, compliance, and legal departments are involved early in the process to address potential concerns and align on objectives.
- Channel selection: Analyze your AI’s use case to decide on the most effective deployment channels, including voice, social media, websites, or in-store displays, that align with your customer interaction strategies.
- Infrastructure decision: Based on your technical requirements and scalability needs, choose between on-premises, cloud, or hybrid deployment infrastructures.
Once your conversational AI is deployed, ongoing monitoring is crucial to measure its effectiveness. But how do we measure the success of its implementation? Here’s where metrics come in:
Metrics to monitor the impact of Conversational AI
Monitoring key performance metrics is essential to gauge the success of Conversational AI. I have made a table to categorize these metrics for effective evaluation:
| Category | Metric | Description |
| User Engagement | Total User Count | Tracks the total number of users interacting with the AI system. |
| Acquisition of New Users | Monitors the number of first-time users engaging with the chatbot. | |
| Active User Engagement | Measures the interaction level of recurrent users. | |
| Conversation Volume | Quantifies the total number of chat interactions. | |
| User Drop-off Rate | Evaluates the percentage of users exiting the conversation prematurely. | |
| Rate of Human Escalation | Measures instances requiring human intervention in conversations. | |
| Conversation Insights | Conversation Analysis | Involves recording and evaluating chat interactions for actionable insights. |
| Adaptive Interaction Strategies | Utilizes conversation analytics to enhance real-time user engagement and experience. | |
| Machine Learning Insights | Predictive Interaction Timing | Leverages machine learning to forecast the best times for user interaction. |
| Product Recommendation Engine | Uses AI to suggest products or services tailored to user preferences. | |
| Performance and Effectiveness | Task Achievement Rate (TAR) | Gauges the efficiency of users in completing tasks via the chatbot. |
| Conversation Flow Completion (CFC) | Indicates the rate at which conversations reach a satisfactory conclusion. | |
| Average Response Time | Measures the promptness of the chatbot in replying to user inquiries. | |
| User Satisfaction and Feedback | Customer Satisfaction (CSAT) | Evaluates user happiness following interactions, typically through surveys. |
| Feedback Mechanisms | Establishes channels for gathering user input to refine conversational flows and responses. | |
| Privacy and Security | Privacy and Security Considerations | Emphasizes handling conversational data with technical safeguards and compliance to regulations. |
A systematic analysis of these metrics is crucial for valuable insights into your conversational AI’s performance as it identifies areas for improvement to enhance user experiences and operational efficiency.
Benefits of conversational AI
Conversational AI can significantly improve user experience and operational efficiency. With natural language processing and machine learning, it can help businesses improve consumer engagement, reduce costs, and streamline decision-making. Here are some key benefits:
24/7 Availability: Conversational AI enables organizations to provide round-the-clock service, ensuring that consumer queries are answered promptly, regardless of time zone.
Scalable solutions: Automated technologies enable businesses to manage more contacts without requiring additional human resources, resulting in more efficient expansion.
Cost-effectiveness: Automating basic queries reduces operational expenses associated with human customer support, freeing up resources for more difficult activities.
Personalized interaction: Conversational AI analyzes user interactions to provide personalized responses and recommendations, increasing consumer satisfaction and loyalty.
Data collection and insights: AI systems collect and analyze user data, providing important insights into customer behavior that help businesses make strategic decisions.
Improved response time: Automated systems provide immediate responses to requests, significantly improving the customer experience by minimizing wait periods.
Each of these advantages contributes to a more efficient, productive, and user-centric approach to customer service and interaction, resulting in corporate success. However, every silver lining has a cloud, and so does conversational AI.
Challenges of conversational AI
While conversational AI has various advantages, it also presents a unique set of challenges that businesses must address when adopting and managing their systems. Some common issues include:
Transparency and bias issues: There are concerns about transparency, potential bias in responses, and fairness of AI decisions. Issues related to user privacy and consent also need to be carefully considered.
Limited interactions: The interaction between AI and users may be limited. In some cases, AI may provide inaccurate or misleading answers.
Originality concerns in education: Using AI for learning and teaching raises concerns about originality and potential plagiarism, especially in education.
Businesses must carefully assess and address these challenges when implementing and managing conversational AI systems. However, despite these challenges, the benefits significantly outweigh the drawbacks, making conversational AI an important tool for organizations looking to improve consumer engagement and streamline processes.
Conversational AI use cases: How top industries are using it
Conversational AI is rapidly changing the way businesses interact with customers across industries, particularly in industries such as healthcare, fintech, real estate, retail, and recruiting.
Conversational AI use cases in Recruiting:
Candidate Screening: Screening candidates through phone calls and resume sorting is time-consuming, and recruiters worldwide have identified this as a major bottleneck in hiring suitable candidates within a given timeframe. AI chatbots have emerged as a solution. In fact, Hilton has reduced their time to fill vacant positions by 90%.
AI can communicate with applicants to gather basic information and qualifications, screening out less suitable candidates and saving time for HR staff.
Scheduling Interviews: Coordinating interview schedules between candidates and interviewers is a time-consuming task and prone to errors. Coordinating manually means juggling calls, checking schedules, and planning everything by hand. But with conversational AI, companies can automate interview scheduling by easily matching candidates’ and interviewers’ availability, making the hiring process much smoother and more efficient.
Onboarding: When new employees come on board, they can easily feel overwhelmed by unfamiliar systems, scattered onboarding processes, and limited access to crucial resources. It’s a lot to navigate all at once, leading to confusion and a rocky start. AI chatbots can simplify onboarding by gathering necessary information and passing it on to new employees. They can also answer questions and direct new employees to company resources, ensuring smoother transition into the organization.
Also read: How we helped a recruiting company streamline their hiring process and improve the user experience for hiring managers and interviewers. Recognizing the potential of conversational AI, our team built a custom chatbot using an open-source platform. Check the full story here: Improving Product Adoption using Conversational AI
Conversational AI use cases in healthcare:
Public Health Awareness: The rapid rise of social media has supercharged the spread of misinformation, and the Covid-19 pandemic, with all its controversies, is a perfect example of how quickly false information can take hold and spread.
AI chatbots combat misinformation in emergency situations by disseminating accurate health information directly on patients’ phones. They can raise awareness on digital platforms and answer questions based on real-world data sets.
Appointment Scheduling and Patient Support: Managing appointments and rescheduling for healthcare providers and patients often requires constant back-and-forth.
AI chatbots simplify this process by handling scheduling, sending reminders, sharing medical reports, and answering common questions—no more phone calls or emails. Cardinal Health’s CHIA is a great example. It helps resolve patient queries about medical products, significantly improving the user experience.
Improving Decision-Making for Healthcare Professionals: People want personalized care from their healthcare providers, but doctors often struggle to deliver it due to time constraints and the sheer volume of patient data. As a result, they can come across as less empathetic and miss the chance to address their patients’ emotional needs.
Advanced conversational AI tools like the GPbRNN chatbot can tailor communications based on patient sentiment, providing more empathy and resources when needed. They also learn continuously from large data sets to better anticipate and respond to patients’ needs.
Conversational AI use cases in Fintech:
Fraud Detection: Rapid digitalization floods the fintech sector with sensitive data. Manually filtering it is a Sisyphean task, especially under time constraints. AI chatbots with NLP capabilities can quickly detect anomalies in user behavior and flag suspicious transactions, reducing financial losses from fraud.
Personal Banking Assistant: Nearly half of the adult population in the US struggles with financial literacy, and the situation is even more challenging for women. Managing personal finances feels like a daunting task for many, leaving them constantly searching for quick, accurate information and personalized advice to help them navigate their financial lives.
Dutch bank ING quickly recognized this challenge and introduced “Inge,” a voice assistant designed to let customers interact naturally, whether they’re asking about loans, transactions, or investment decisions. Inge goes beyond answering questions—it can analyze data and offer personalized financial advice, making banking simpler and more intuitive for customers.
Collecting Feedback: Long feedback forms and surveys can be a real hassle to fill out. Fintech companies can tap into AI-powered feedback bots to gather user sentiment and pinpoint areas for improvement, making the customer experience smoother and more intuitive.
Conversational AI use cases in Real Estate:
Lead Capture and Management: Unproductive leads, and clunky management processes can really bog down sales teams, creating bottlenecks that lead to missed opportunities and follow-up delays. Conversational AI bots, by acting as the first point of contact, can collect valuable information from potential buyers or tenants. From those insights, they can then categorize leads and streamline the entire sales process.
Personalized Property Recommendations: Manually matching buyers with their specific criteria can be a tedious process, often leaving loose ends and unresolved threads. AI chatbots collect user preferences—such as budget, region, and property type—and create tailored profiles to recommend curated property options, ultimately boosting conversion rates.
Scheduling Property Tours: Coordinating property tours can be a real headache for both buyers and owners, with back-and-forth communication eating up valuable time. These scheduling conflicts and inefficiencies can make the process more frustrating than it needs to be, slowing down the path to finding the right match. Just like in healthcare, chatbots can check availability of both buyers and owners to schedule tours.
Conversational AI use cases in Retail:
Improving the In-Store Experience: In-store shoppers at places like Walmart or Costco often find themselves wandering the aisles, struggling to locate a product with the exact specifications they need. This can quickly turn into a frustrating experience, leaving them with a sour taste from the shopping trip. An in-store AI chatbot can significantly enhance the shopping experience by offering real-time product recommendations and answering questions about availability and sizing. It’s like having a helpful assistant right at your side, boosting customer satisfaction and making the trip more enjoyable.
Order Tracking: Customers, fueled by the excitement of receiving something valuable or the fear of getting scammed, frequently stress over delivery status. Conversational AI chatbots, powered by NLP and ML, offer real-time updates, easing tracking and reducing the need for customer support.
Better Decision-Making: For retailers, driving up ROI is all about understanding demand and stocking the right products to meet it. Events like Black Friday or Christmas are perfect examples where a retailer’s profit really depends on how well they have anticipated and understood customer demands. If they get it right, they are in for big gains; if not, they could lose out on a significant chunk of revenue. Read our blog on Conversational AI Use Cases and Benefits Across Top Industries for in-depth insights into its use cases and benefits across major industries.
Conclusion
Conversational AI is completely changing the game for businesses. It is like a super tool that opens up new avenues of communication between businesses and their customers. From healthcare to retail, AI is making things easier and better for everyone.
With AI on their side, organizations are experiencing significant benefits in productivity, customer satisfaction, and even decision-making. It’s clear that companies that are utilizing this technology are positioning themselves for success. As AI advances, the possibilities become limitless.
Frequently Asked Questions (FAQs)
How can I create conversational AI?
To develop a conversational AI that delivers results, you can follow these steps:
- Define your objectives.
- Ensure alignment across company functions.
- Decide on your approach to building conversational AI.
- Plan your content strategy.
- Establish necessary collaborations and secure approvals.
What sets conversational AI apart from chatbots?
While both terms are closely related, the key distinction lies in their scope and functionality. Chatbots are typically designed to automate specific tasks, whereas conversational AI encompasses a broader range of technologies aimed at facilitating more complex and human-like interactions.
What are the primary obstacles in developing conversational AI?
The main challenges stem from processing language inputs, whether text or voice, due to the vast array of dialects, accents, and languages globally. Additionally, capturing human nuances such as tone, emotions, and sarcasm presents significant difficulties.
How does conversational AI differ from NLP?
Conversational AI is an umbrella term for technologies that enable machines to conduct conversations in a manner similar to human interactions. Natural Language Processing (NLP), a crucial component of conversational AI, specifically focuses on the machine’s ability to understand, interpret, and produce language in a way that resembles human communication.









