

While AI coding tools promise a significant boost in engineering velocity, many organizations find it simply the illusion of a great first week followed by a flat line.
This pattern plays out on almost every single engineering team that I work with. Week one is great. Boilerplate that used to take an hour to write is drafted in minutes. Engineers feel fast. Output looks great. Everyone’s happy. Then the curve flattens. The second week looks pretty much the same as the first week. The second month looks pretty much the same as the first month.
AI is still fast, but every time you start a session you are cold. Because the model doesn’t have any institutional knowledge about your organization’s coding conventions, or code quality bar. That means the engineer explains the same architectural concerns and review criteria over and over again.
This is the “information gap.” When this gap is left wide open, every session feels like “Session One” and your gains don’t compound. And when gains don’t compound, teams instinctively blame the model. That’s the wrong diagnosis.
To understand how to break this plateau, we did a month-long experiment.
The stress test
We spent several months building an enterprise integration platform from scratch using Claude Code as our AI pair programmer, tracking every session in detail. Dozens of API endpoints. Real-time webhook processing. A full React dashboard.
We chose enterprise integration work deliberately because it stress-tests AI-assisted development in ways simple projects can’t.
The Goal: To answer the question our clients ask most: How do you make AI-assisted development accumulate value over time instead of plateauing?
Here’s the short version of what we found: the model wasn’t the bottleneck. The process around it was. And within the process, the biggest single variable was the quality of what we put in – not what the AI put out.
The AI was not producing unpredictable output. It was producing predictable output based on insufficient input.
That reframe changed everything. Our data identified two specific shifts that broke the plateau. Neither had anything to do with choosing a better model.
Why our gains were plateauing
Across our earlier sessions, we saw the same pattern repeat.
In every session our engineers were spending the first 10 to 15 minutes re-establishing context. Re-explaining the coding standards. Re-explaining the middleware patterns, the database schema conventions, and the testing requirements.
By round three or four of a review cycle, the output was solid. Then the session ended and all of that context evaporated. The next session started from scratch.
About a third of our early sessions ended with work still incomplete- not because the AI failed, but because there was no mechanism to carry what each session learned forward into next one.
Now multiply that across a team of ten engineers. Each one establishing context a different way. Each one applying a little different interpretation of ‘production-ready.’ The results isn’t just wasted setup time. It’s ten different quality standards accumulating quietly in the same codebase.
That was our plateau. It was not a model problem. It was a memory and process problem.
Fix one- Stop prompting. Start process engineering
The most critical reframe we made was this: the real workflow of AI pair programming is not ‘prompt and ship’. It’s a cycle- prompt, review against your standards, revise, repeat. The quality is in that cycle, not in the first draft.
But if you are essentially rebuilding the context for that cycle from scratch every session, you are not doing AI-assisted development. You are doing costly, repetitive setup with some AI output mixed in.
The change: Claude Code Skills as process artifacts
We fixed this by building Claude Code Skills- reusable, version-controlled commands that encode exactly how our team works. Not prompt templates. Not guidelines in a Notion doc. Actual executable artifact that live in the repository.
What this looks like in practice:
- One skill triggers our full estimation workflow – complexity scoring, dependency mapping, effort projection- in a single command.
- Another runs a structured code review against our embedded checklist: SOLID compliance, OWASP Top 10 checks, test coverage thresholds, API contract validation.
- A third orchestrates a multi-file audit using parallel AI agents- one validating code quality, one verifying spec alignment, one running the jest + Supertest test suite – simultaneously.
The critical distinction between this and normal prompt engineering: Skills are artifacts. Version-controlled. Anyone on the team can run them. The output is the same whether it’s a senior engineer or someone on their second week.
That matters more than it sounds. Prompt engineering improves your next session. Process engineering improves every session that follows- for every engineer on the team, indefinitely.
What data showed

Over time, the test suite expanded to cover every major integration path with minimal friction- tests that would have been tedious and inconsistent under ad-hoc prompting became a natural byproduct of the Skills-driven workflow. Documentation followed the same pattern: generated as output, not maintained as a separate task.
The finding that surprised us most: architecture quality improved as speed increased. When our engineers stopped fighting setup and boilerplate, they spent more time thinking about design. The AI didn’t replace engineering judgement – it freed engineers to apply it at a higher level.
Diagnostic checklist
Before switching models or tools, check your process.
If your gains are not compounding, the bottleneck is likely not AI.
It’s how you are using it

Fix two –Audit the developer before you blame the model
Once our process automation was in place, we expected the remaining quality issues to trace to the model limitations. We went through every session systematically, looking for root causes.
The data pointed somewhere we did not expect.
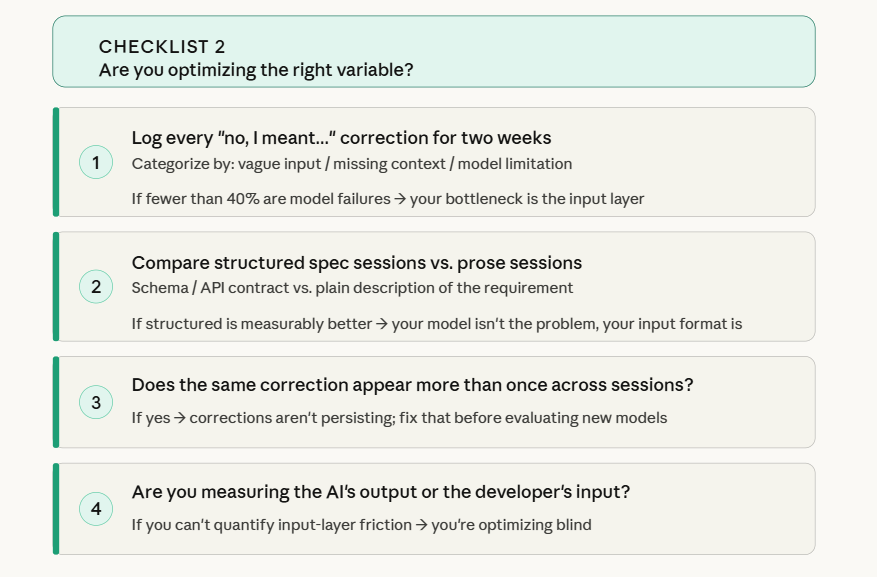
We tracked 28 buggy-code incidents and attributed them to Claude Code. Here’s what we actually found when we examined the sessions: the majority clustered in sessions where our prompts were vague or incomplete. Engineers described what they wanted in general terms instead of specifying API contract, the expected webhook payload shape, or the exact database schema the output needed to conform to.
One concrete example from our session
An engineer prompted ‘build the sprint analytics endpoint.’ The Claude Code produced a reasonable implementation- but it fetched data through individual queries instead of using the platform’s bulk search endpoint, creating a Classic N+1 call pattern that would have hit rate limits in production within minutes.
The same task, run later in our experiment with a precise spec- exact API route, query approach, validation schema, error handling requirements- produced production-ready output on the first cycle.
Same model. Same task. Different input specificity.
Across hundreds of prompt-review-revise cycles in our sessions, over 90% produced satisfactory output. But friction data showed we were leaving roughly 30% of productive capacity on the table. When we traced that waste back, it consistently pointed to input quality- not model capability.
In our data, the quality ceiling was set by what we gave the AI, not by what the AI could do.
This confirmed what we had suspected but never measured: the quality ceiling is set by the input, not the model. The information gap we described earlier was not theoretical- it was the direct cause of nearly every quality issue we tracked. When the input was precise, the output was precise. When the input was vague, the output was predictably vague.
The change: structured memory and persistent corrections
Three changes we made- each measured independently:
- Structured memory in Claude Code. Instead of dumping context into unstructured session notes, we organized persistent memory into three categories: decisions (why we chose REST middleware over RPC-style handlers for the webhooks), corrections (never generate third-party API calls without validating against the provider’s schema first), and process rules (always run the Jest integration suite before marking a ticket-lifecycle endpoint complete). Claude Code’s memory system retrieves structured context at session start – the AI begins with institutional knowledge instead of a blank slate.
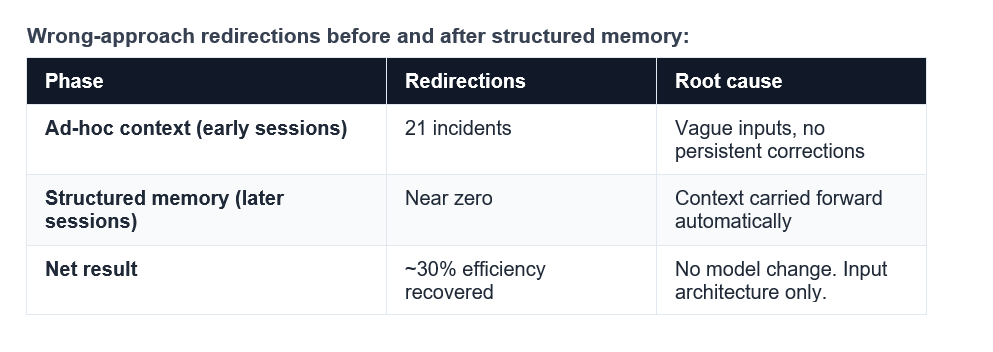
- Persistent corrections as a permanent context. This single change had the largest measured impact. Every correction — every “no, use the bulk endpoint, not individual calls” or “validate the webhook signature before processing the payload” – was recorded once in Claude Code’s memory and carried forward permanently. Wrong-approach redirections dropped from 21 in the early phase to near zero after implementing structured memory. Same model. Same tooling. The only variable was the input architecture.
- Developer input auditing before model-shopping. Before considering a model upgrade or tool switch, we reviewed the engineer’s own session patterns first. The data consistently showed that improving input structure resolved most quality issues without changing anything else — no provider switch required.
What the data showed
Diagnostic checklist
Before blaming the model, audit the input. Most quality issues trace back to what the developer gave to AI –not what AI was capable of.
What this means for engineering teams evaluating AI adoption
The experiment confirmed a pattern we see across client engagements: AI-assisted development delivers sustained value only when two conditions are met.
First, process must be encoded – not repeated.
In this experiment, context setup dropped from 15 minutes per session to zero. That improvement didn’t rely on individual effort- it applied automatically to every subsequent session and every engineer using the system.
Teams that treat AI interactions as ad hoc will see gains plateau within weeks. Teams that invest in codifying workflows into version-controlled automation create a system where every session starts from an established standard- not from scratch.
Second, developer input must be measured before model output is blamed.
Wrong- approach redirections dropped from 21 to near zero without changing the model or tooling. The only variable that changed was the input structure.
Across both this experiment and client delivery work, the pattern is consistent: most AI quality issues trace back to input clarity, not model capability.
Before upgrading providers, teams should audit how they are structuring and interacting with the model.
The common thread across both shifts is clear:
Neither required a better model.
Neither required new tools.
Both required changing how the system and the people using it operate around the AI.
There is also a practical distinction teams need to make:
- Constrain for conformance when the goal is reliable, standard-meeting output
- Release for exploration when the goal is to navigate a broader solution space
Without this, teams either sacrifice reliability or limit the value AI can generate.
The teams that moved ahead will not be the ones with the best models.
They will be the ones that build systems where context persists; corrections accumulate, and standards carry forward across every session.
These are not theoretical ideas.
They are engineering decisions that directly affect delivery timelines, system reliability, and whether AI adoption results in a short-term productivity gain or a durable operational advantage.
The process frameworks and measurements practices described here are already applied across our delivery work. If your team is working through similar challenges, it’s a conversation worth having.









