

IBM Watson’s oncology feature was a $62 million setback. Air Canada’s chatbot became a legal liability. Taco Bell’s and McDonald’s drive-thru AI failed to handle edge cases. These are some generative AI POCs that, when they failed, raised several eyebrows. But these are not exceptions. Rather, this is a more common occurrence in the GenAI POC-to-production journey. 95% of the GenAI projects fail. And yet, generative AI is moving rapidly from research labs into enterprise experimentation. Organizations across industries are launching pilots for AI assistants, document processing tools, customer support automation, and knowledge discovery platforms.
Among the major reasons, the fear of losing out in the AI race and the promise of high returns are primarily driving these enterprise moves. However, this growing excitement can hardly mask the widening gap between GenAI experimentation and real enterprise adoption.
Organizations successfully building promising proofs of concept (POCs) is not a rare occurrence. But far fewer manage to transform them into reliable, scalable production systems. A prototype might work well in a controlled demo, but deploying it within real enterprise workflows introduces challenges that are often underestimated.
The consequences of stalled POCs go beyond technical setbacks. They include losses incurred in engineering effort, infrastructure, and budget for experiments that never scale. If a company fails repeatedly in its endeavors to launch successful GenAI products, it develops organizational skepticism, where leaders become more cautious about future AI initiatives.
I have been working on multiple GenAI projects since the launch of ChatGPT in November 2022, and I have identified some major pointers to explain why GenAI projects fail. Models are not always at the top of generative AI POC challenges. The challenges mostly arise from business alignment, data readiness, evaluation practices, cost management, and system integration.
1. Unclear Business Value
I worked on a project where we were asked to extract information from technical documents for a construction company. Such companies often engage experts to review these documents manually, which is a time-consuming task. We could have simply built an information extractor, and that would have served the purpose. But we went a step further and made the system learn how to read technical documents and derive expert insights. This removed the need to engage experts and saved their bandwidth for more important tasks.
Product owners often come to teams with specific GenAI requirements. Meeting them might tick off some tasks from the list but doesn’t always guarantee value. A task is activity-focused, but a value-delivering task is outcome-focused.
The excitement around GenAI often encourages teams to start experimenting before fully identifying the problem they want to solve. As a result, organizations build technically impressive prototypes that lack a clear operational impact. That’s the first level of the problem. Sometimes, they identify the problem but don’t come up with requirements that match user expectations. That’s the second layer. In order to deliver impact, the task should be aligned with what users expect.
Many early GenAI pilots were centered around internal chatbots or document summarization tools. These demonstrations performed well in controlled environments. But when leadership asked how the bot would improve productivity or reduce operational costs, the answers were often vague because the scope or bottlenecks for scaling were not clearly defined. Sometimes, teams used traditional metrics to measure performance, which was again a setback, as new solutions require new metrics to evaluate productivity and cost.
Without measurable outcomes, it becomes difficult to justify the investment required to move from a prototype to a production-grade system.
In our project, we ensured the system extracted only what was relevant from permit plans and automatically validated those values against regulatory requirements. This clarity of business objectives helped the project move beyond the POC stage. The goal was not simply to demonstrate AI-based extraction but to reduce manual review effort and accelerate compliance verification. Because the impact was measurable, stakeholders could clearly see the operational value.
This experience reinforced a key lesson: GenAI initiatives succeed when they are tied to specific business outcomes. Technology experimentation alone is not the way forward.
To increase your chances of success, you must define the following before starting:
- measurable business metrics
- baseline performance of existing workflows
- expected efficiency gains or cost savings
- clear success criteria for the AI system
2. Data Readiness Challenges
Data readiness is a major roadblock in the GenAI POC-to-production journey. GenAI systems rely heavily on data to interpret or retrieve information from enterprise documents. Even when the business use case is clear, this can disrupt the flow and outcome.
Take Zillow, for example. Its iBuyer started with promising results, primarily because it was tested with structured data. But later, it failed to interpret unstructured, qualitative signals like home-specific features and local nuances.
In one of my projects, we were asked to use GenAI to generate structured quotations for industrial components from unstructured customer emails and attachments. We faced similar GenAI implementation challenges.
Scaling GenAI to production depends heavily on data readiness. Data with minimal noise is not just beneficial for system performance but also for cost efficiency. However, most enterprise data environments are fragmented. Such systems often work with information distributed across multiple internal systems, stored in inconsistent formats, or embedded in unstructured documents.
Customers used to email requirements with technical specifications or product documentation to the sales team. The team manually interpreted these emails, identified appropriate parts, and prepared quotations. Our GenAI system automatically analyzed incoming emails, extracted requirements from attachments, and produced structured quotation data. It performed well during experimentation, but the biggest challenge was not the model—it was data variability. Emails arrived in many different formats; attachments included PDFs, spreadsheets, and scanned documents; and product catalogs were distributed across multiple internal systems.
Organizations preparing for GenAI adoption should invest early in document ingestion pipelines, structured knowledge repositories, metadata and indexing systems, and data governance and access policies. They can start by creating a simple readiness checklist to determine whether the data environment is suitable for GenAI, using the following questions:
- Are enterprise documents accessible through reliable pipelines?
- Are knowledge sources searchable and indexed?
- Are there clear policies governing sensitive data access?
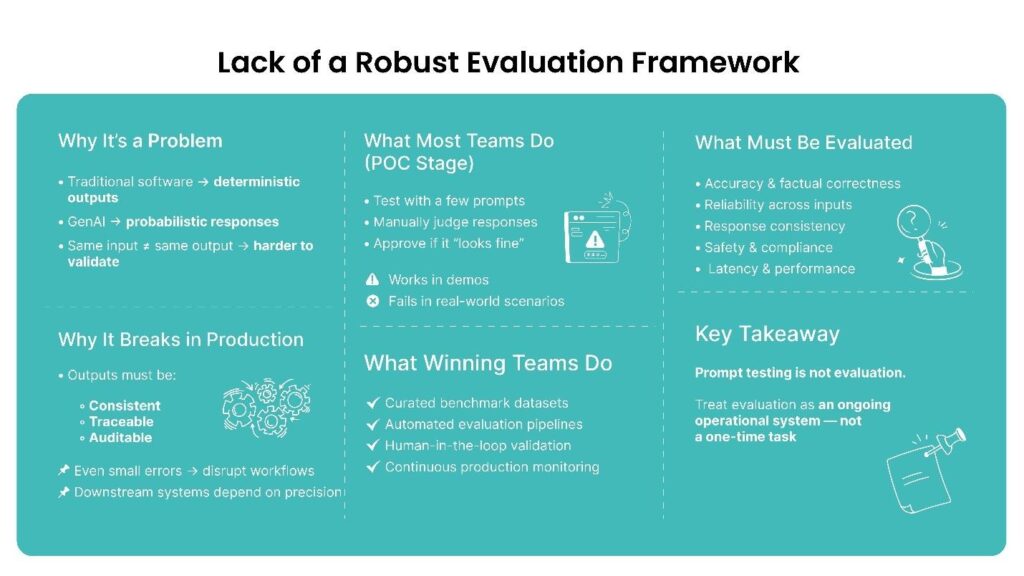
3. Lack of a Robust Evaluation Framework
Testing GenAI systems is fundamentally different from testing traditional software. Conventional applications produce deterministic outputs: the same input always produces the same result. GenAI generates probabilistic responses, which makes evaluation more complex.
Many GenAI POCs rely on informal testing, where developers manually try a few prompts and assess whether the responses seem acceptable. While this approach works during early experimentation, it becomes unreliable when the system must handle real-world inputs. For instance, in 2023, Koko conducted an empathy experiment where the AI system drafted highly accurate responses. However, as a case of semantic blindness, the company failed to account for the human-to-human connection necessary in a psychological evaluation, which led to a decline in its acceptance.
In production environments, organizations must evaluate GenAI systems across multiple dimensions, including accuracy and factual correctness, reliability across diverse inputs, response consistency, safety and compliance, and latency and performance.
Let me elaborate on this point further with a document extraction system. The requirement in such a case is not only to extract data but also to ensure that the results are consistent, traceable, and auditable. Even small inaccuracies can disrupt downstream workflows. Similarly, in automated quotation generation, responses must be structured and precise because other systems rely on that data for pricing and order processing.
Such scenarios make simple prompt testing insufficient. Organizations that successfully deploy GenAI systems typically establish structured evaluation frameworks that include curated benchmark datasets, automated evaluation pipelines, human-in-the-loop validation, and continuous monitoring in production.
Evaluation must not be treated as a one-time task but as an ongoing operational process.
4. Cost Unpredictability
Among all the other enterprise GenAI challenges, cost unpredictability often appears after the POC phase. GenAI systems introduce new cost structures that many engineering teams do not understand. Token consumption, inference frequency, and model selection often drive expenses instead of predictable infrastructure costs.
At an early stage of experimentation, usage levels are typically small. But once you deploy the system across an organization, demand can increase dramatically. For example, the number of engineers using an AI-powered assistant during testing is far less than the thousands of employees across multiple departments who use it once the bot goes live.
While trying to understand why GenAI projects fail, we have realized that a lack of careful planning often becomes a bottleneck for scaling GenAI to production. This can lead to significant cost increases. Teams often underestimate expenses associated with large context windows, high-frequency API calls, retrieval pipelines for knowledge systems, and real-time inference requirements.
To avoid cost surprises and other GenAI deployment challenges, organizations should incorporate cost planning and monitoring early in development. Practical strategies should include forecasting realistic usage patterns, optimizing prompts and context sizes, using smaller models where possible, and implementing usage limits and monitoring tools.
When cost management is treated as part of system design, GenAI solutions remain sustainable as they scale.
5. Integration Complexity
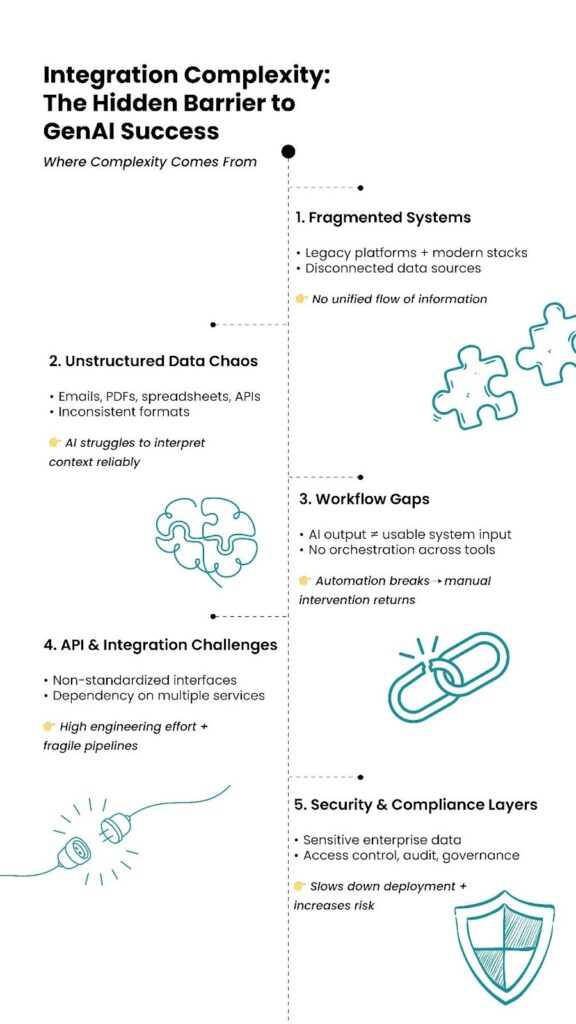
Working in silos and working in an enterprise workflow are not the same. This, among other generative AI deployment challenges, often hits hard when it comes to delivering value. A perfectly working GenAI model can completely collapse in an enterprise ecosystem if it is not already tested in similar conditions.
Organizations operate complex technology ecosystems with legacy systems, internal APIs, compliance requirements, and security controls. Integrating AI capabilities into these cannot be the result of a plan on the fly. The process requires careful architectural planning. AI-native modernization often solves this problem, as it keeps the ground prepared for future AI integrations.
I have shared two case studies earlier. In both the document extraction and quotation generation projects, the GenAI model represented only one component of the overall system. A large portion of the engineering effort was spent on building the surrounding infrastructure, including document ingestion pipelines, workflow orchestration systems, verification layers for regulatory rules, and APIs for downstream enterprise systems. The supporting architecture often determines whether the project reaches production, not the AI model itself.
You can reduce integration challenges by designing systems with AI integration in mind from the very beginning. Key strategies include building modular AI services, introducing orchestration layers for AI workflows, standardizing APIs for enterprise integration, and implementing monitoring and observability early.
When you treat GenAI as part of your larger software architecture, you improve your chances of deployment success.
Conclusion
Most failures are not caused by limitations in AI models. Instead, they stem from unclear business objectives, weak data foundations, inadequate evaluation frameworks, unpredictable costs, and integration complexity. Organizations that successfully deploy GenAI systems recognize that building production-ready AI requires more than experimentation. It requires a team that is well-versed in AI, strong engineering practices, robust data infrastructure, and clear alignment with business outcomes.
As enterprises move beyond the initial wave of AI experimentation, the focus must shift toward building reliable, scalable AI systems that integrate deeply into real business workflows. Those that address these foundational challenges will be far better positioned to turn promising GenAI experiments into sustainable operational capabilities.









