

Everyone wants to “add AI” to their product stack. But peel back the layers and you’ll find the same story in most organizations: fragmented datasets, undocumented pipelines, missing context, and noisy warehouses that struggle with even basic reporting.
It shows up in numbers too.
- 42% of companies say half of their AI projects stall or fail because their data isn’t AI-ready.
- Gartner estimates that by 2026, 60% of AI initiatives built on unready data will be abandoned entirely.
And this is exactly what our Principal Architect, Ratnesh Parihar, has been calling out in his deep-dive webinar “Is Your Data Ready for AI? Common Pitfalls and Practical Solutions.”
“If your data systems and frameworks don’t succeed, AI won’t fail quietly — it will fail loudly.”
And that’s exactly what we’ve seen across enterprise and startup implementations. Teams rush to ship agents, copilots, RAG systems, and LLM-powered workflows—but the data foundation underneath is brittle, incomplete, inconsistent, and ungoverned. And that becomes a death sentence for any LLM or agentic AI implementation.
After working through dozens of implementations, Ratnesh broke the core of the problem down into 7 non-negotiable data readiness checks — all observed firsthand in real pipelines where skipping even one led to broken pipelines, corrupted embeddings, unusable recommendations, compliance issues, or multi-million-dollar rework.
“When I was constructing my whole experiences with AI and the data pipelines I kind of converted into the seven pointers… this is the seven-pointer checklist whether your system or your data warehouse or your data pipeline is ready for the AI or not.”
And he’s right.
And the timing couldn’t be more critical.
Why these 7 data readiness checks matter now
Deep learning gave us powerful models… but GenAI changed the rules entirely.
As Ratnesh put it:
“What we should be prepared as data engineers or data architects is — we need to make sure we follow these trends, we follow these tools, we keep on building these systems, start learning things.”
The next wave of AI winners won’t be determined by who fine-tunes better or who uses the latest model. It’ll be determined by:
- the quality of your data
- the context attached to it
- the trustworthiness of your pipelines
- the discoverability of your semantic layers
- the real-time readiness of your architecture
If you want AI-native products — copilots, personalized agents, automated workflows, AI-powered search — you need a data architecture that can feed an LLM the right information, at the right time, with the right context, and in the right format.
This is where his 7-point checklist to assess data infrastructure comes in, and why it matters now more than ever.
7-point checklist for AI-ready data
1️⃣ Unification- Is your data centralized and accessible through single connection?
Most AI projects die at the first step: connecting to data. Research and surveys consistently highlight data access and preparation as the most time-consuming and challenging aspects of an AI/ML project lifecycle.
Startups and enterprises alike store data across:
- OLTP systems
- legacy SQL stores
- microservices
- chat logs
- third-party SaaS tools
- data lakes
- warehouses
- logs and queues
- blob storage
This fragmentation kills AI initiatives.
“The first readiness check is simple: can your team access all critical data through a single unified access point?” — Ratnesh
Why it matters
If your AI app needs inventory, order history, vendor profiles, user behavior, and reviews, but each lives in a different place, your LLM:
- won’t have complete context
- will produce incorrect summaries
- will generate hallucinated recommendations
- will throttle your engineering team with constant schema digging
Quick test
If your backend dev asks, “Where do I hit for this data?” and you can’t answer in 10 seconds, you already failed Check #1.
2️⃣ Discoverability- Can your team find data without directly accessing it?
This is one of the most underestimated issues. Industry consensus supports this; the time spent by data professionals searching for and understanding existing data is substantial. This friction severely slows down AI development cycles.
Teams spend hours reverse-engineering naming conventions, schema mismatches, undocumented tables, and old ETL jobs.
AI makes this dramatically worse because:
- LLMs need clean chunking
- Embeddings need consistent semantics
- Prompts need structured sources
“People should be able to discover your data without opening the tables. If they need to inspect raw data to understand structure, you’re not AI-ready.” — Ratnesh
Discoverability requires:
- Data catalogs
- Lineage
- Ownership
- Classification
- Semantic layers
- Schema registries
Without this layer, every AI project becomes guesswork.
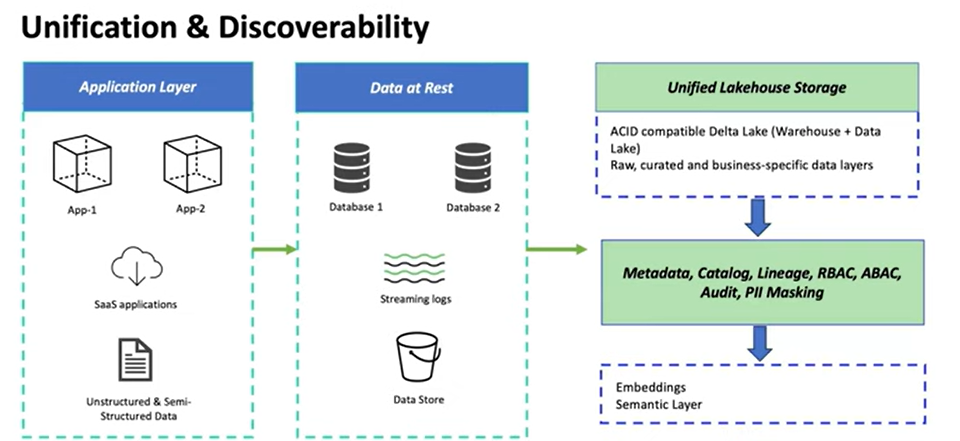
3️⃣ Quality & reliability- Whether the quality and reliability checkpoint has been implemented in the place?
This is where most hallucinations originate—not from the LLM, but from bad data feeding it.
Ratnesh says it plainly:
“If your data is not trustworthy, your model becomes more dangerous, not more intelligent.”
LLMs are nondeterministic. They amplify whatever you give them—clean or dirty.
You need:
- schema validation
- deduplication
- missing value handling
- outlier detection
- consistency checks
- audit trails
- PII masking
- SLAs for freshness
“Quality checkpoints must be implicit and by design—not ad-hoc fixes welded into your pipeline.”
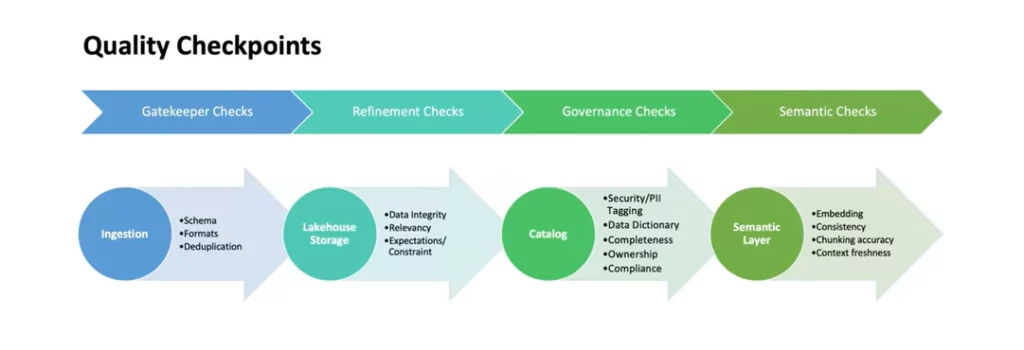
Data lakes (especially Delta Lakes with DBT) help enforce these constraints automatically—immutability, versioning, lineage, and enforced schema evolution.
If you’re still using an old warehouse without governance, you’re introducing hallucinations long before the LLM is even called.
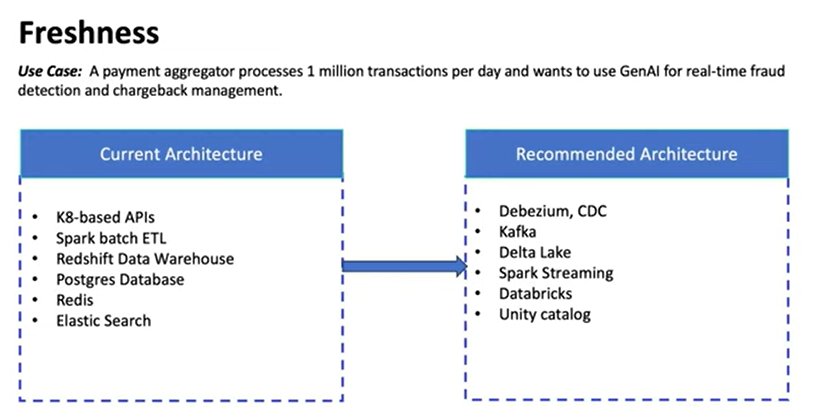
4️⃣ Real-time access: Can your systems serve live data to LLMs & agents?
You can’t build modern AI experiences (support copilots, fraud detection, personalization, or decision intelligence) on stale data. AI applications like fraud detection, personalized recommendations, and live customer support agents require the most current context to make accurate and relevant decisions.
Relying on data that is hours or days old (typical of traditional batch ETL processes) severely limits the effectiveness and relevance of these AI systems.
Ratnesh’s e-commerce case study makes this brutally clear.
The client wanted:
- A support chat assistant
- Recommendations for agents
- Real-time sentiment
- Real-time retrieval
But the system only had batch ETL, outdated data catalogs, and fragmented stores.
“If your bots or AI agents cannot fetch real-time context, you will always land in the hallucination zone.” — Ratnesh
Ask yourself
Can your LLM retrieve:
- current order state?
- latest transactions?
- updated inventory?
- most recent conversation thread?
If the answer is no, your AI feature will behave like a clueless intern who’s always one day behind.
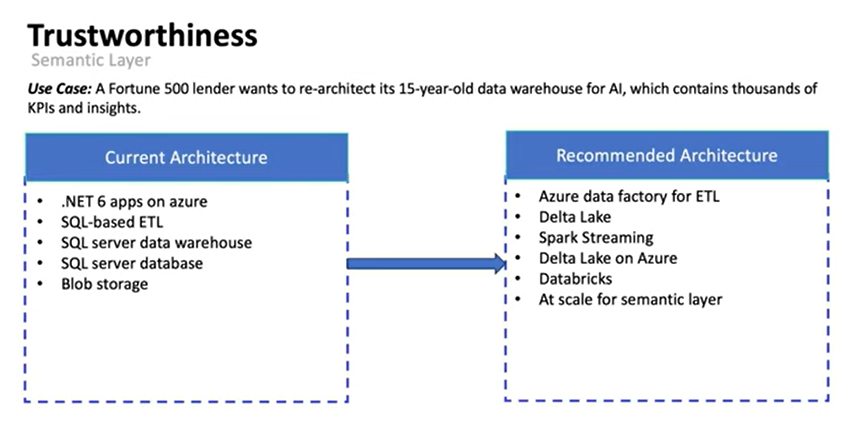
5️⃣ Trustworthiness- Is your data credible and complete enough to generate reliable AI outputs?
Trustworthiness goes beyond “quality.”
It asks:
- Is the data complete?
- Is the source authoritative?
- Are semantics consistent?
- Do multiple tables contradict each other?
“If your data gives mixed signals, the LLM will hallucinate. It’s not the model. It’s your inconsistency.” — Ratnesh
An LLM cannot discern which of two conflicting data sources is correct; it will simply blend or choose one, often producing a “mixed signal” output.
In the e-commerce case:
- product reviews conflicted with vendor ratings
- warranty data contradicted support logs
- multiple sources stored refund reasons differently
One missing trust layer, and the AI support assistant started giving wrong advice.
AI is a multiplier. If your raw material is flawed, AI magnifies the flaw.
6️⃣ Scalability & cost awareness- Are you prepared for LLM-heavy workloads?
Many teams underestimate the cost side of AI. Initial proof-of-concepts often use readily available cloud resources, but scaling these to production-level usage reveals significant recurring costs associated with computation (GPU usage for inference/training), vector search, and data processing.
RAG pipelines, embeddings, vector search, streaming updates—all come with recurring costs.
- Vector search and embeddings require specialized databases (vector dbs) and computational power for data embedding and searching, adding infrastructure costs.
- Streaming updates require real-time processing infrastructure, which is inherently more complex and costly than traditional batch systems.
“If you’re building on top of premium LLMs, you’re offering a premium product. The question is: will users pay for it?”
If the answer is no, you must rethink:
- your architecture
- your latency constraints
- your prompt design
- your inference routing
- your embedding refresh frequency
Because using expensive, high-end commercial LLMs (like OpenAI’s GPT-4 or Anthropic’s Claude 3 Opus) incurs per-token costs that can quickly become economically unviable for standard enterprise applications where the user value doesn’t justify the operational expense.
Ratnesh is blunt about this:
“If you want a normal enterprise application, but you use premium AI patterns, you’ll burn cash unnecessarily.”
Scalability isn’t just about infra. It’s about economic sustainability.
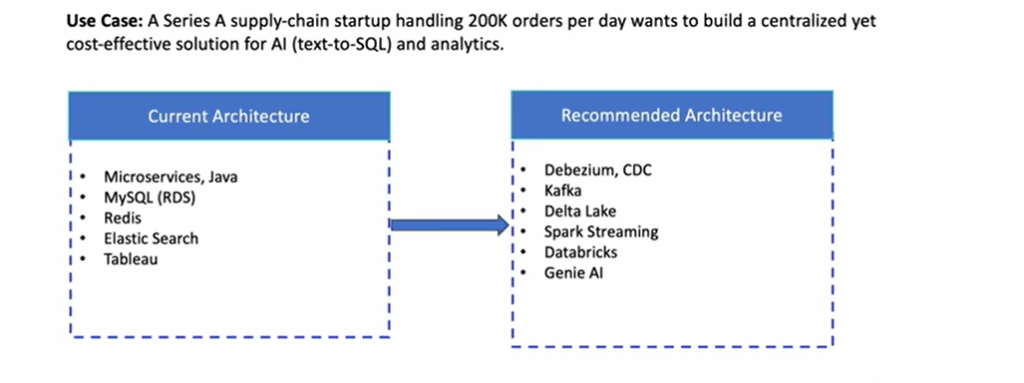
7️⃣ Contextualization- Does your data encode the rich context AI needs?
This is the silent killer of most AI deployments.
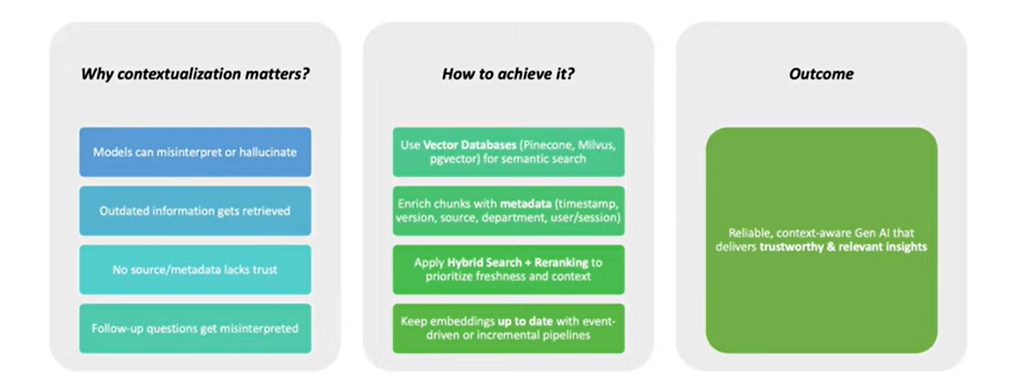
Most companies have no consistent structure for:
- user context
- tenant context
- product context
- vendor context
- review context
- transaction context
Data for a “product” might exist in an inventory system, a sales log, and a support database, but without a shared, consistent structure, the AI cannot link these pieces together into a single, rich understanding.
In the e-commerce example, wrong or missing context caused:
- bad recommendations
- incorrect summaries
- skewed embeddings
- hallucinations under ambiguity
LLMs rely heavily on the context provided in their input window to generate meaningful responses. Without context, an LLM might misinterpret a sales spike as fraud or a positive trend, leading to poor decisions. It cannot discern the nuance or intent behind the raw data.
Ratnesh puts it clearly:
“If your system isn’t built to preserve context, everything looks like a vague text blob to an LLM.”
Let’s take another case study
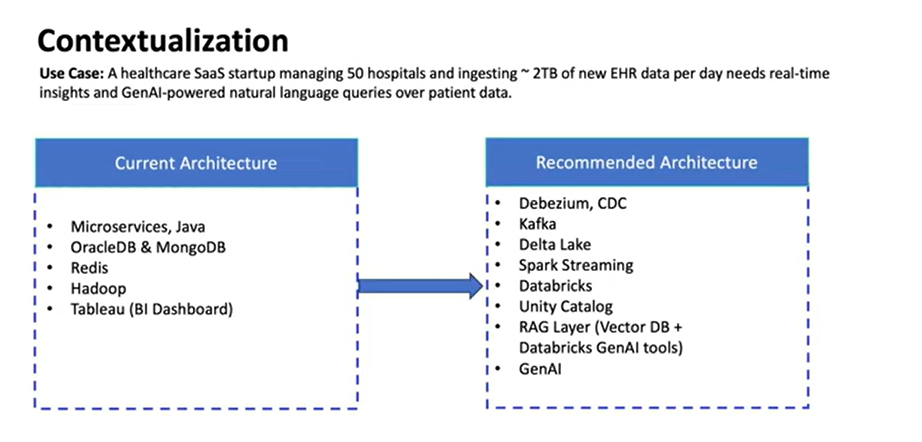
LLMs need context-rich data to chunk, embed, rank, and answer accurately.
Without it, your AI behaves randomly—sometimes correct, often confidently wrong.
Contextualization is a non-negotiable requirement for moving AI from experimental pilots to reliable, production-grade applications.
How modern data lakes solve many of these problems automatically
Modern Delta Lakes (combined with DBT and strong governance) embed best practices into the system:
✔️ Immutability
Prevents accidental overwrites and duplication.
✔️ Automatic schema enforcement
Prevents broken pipelines.
✔️ Versioned data
Enables rollback and auditability.
✔️ Built-in quality rules
Eliminates manual fixes.
✔️ Cataloging + lineage
Drives discoverability.
✔️ Uniform layers (raw → curated → semantic)
Provides a clean path for embedding generation.
“The quality of embeddings, the accuracy of chunking, and the consistency of semantics — all depend on how clean your lakehouse foundation is.”
This is why Ratnesh recommends embedding generation on curated semantic layers, not raw stores or old warehouses.
Why most companies skip these 7 checks
Because they assume AI sits “on top” of the product.
It doesn’t.
LLMs, agents, copilots, and RAG pipelines rely heavily on:
- clean inputs
- fast retrieval
- unified structures
- consistent semantics
- trustable context
AI is not a feature — it’s an architectural shift.
“To build systems that are first-time-right, the foundation must be first-right by design.” — Ratnesh
Your AI can only be as good as your data
If you skip these seven readiness checks, you’re not just slowing down innovation — you’re sabotaging your AI stack.
Here’s the uncomfortable reality:
- You can’t prompt-engineer your way out of bad data.
- You can’t fine-tune your way out of inconsistent semantics.
- You can’t eliminate hallucinations if your data is incomplete.
- You can’t achieve real-time AI on top of batch pipelines.
Companies that succeed with AI don’t start with the model. They start with the data foundation.
Conclusion
Before you build your next AI feature, ask: Is my data truly AI-ready? Or am I hoping the model will compensate for the gaps?
As Ratnesh aptly puts it:
“AI will not fix bad data. It amplifies it. If you get your seven checks right, most of your AI challenges disappear before they even show up.”
A reliable AI foundation requires reliable data engineering. We provide the foundational engineering expertise to build a clean, curated data layer. This ensures that when you move to embedding generation and complex AI features, you are building on a reliable foundation, not amplifying existing errors.
Ensure Your Data Is AI-Ready. Partner with Talentica.
Take the first step toward a robust, AI-native future.
Talk to Our AI-Native Engineers
Let’s Connect and build AI that ships, reliably.









