


Modern data systems demand real-time synchronization, reliability, and scalability- qualities that traditional ETL pipelines often fail to deliver. To address these limitations, I along with my team turned to the Declarative Lakehouse Pipeline approach powered by Delta Lake on Databricks.
Delta Lake is an open-source storage framework that brings ACID transactions, schema enforcement, and data reliability to data lakes. Built on top of Parquet files and compatible with tools like Apache Spark, it enables both batch and streaming workloads on the same data.
When combined with tools like Debezium, DeltaLake’s capabilities extend even further. Debezium makes it easier to stream CDC into raw delta lake format data in bronze layer of a medallion architecture. This ensures freshness and consistency across systems without relying on periodic bulk refreshes.
If you are a data engineer tasked with building or modernizing ELT pipelines, this walkthrough will not only provide practical implementation details but also demonstrates the architecture and design principles needed to scale efficiently while keeping data trustworthy.
The problem
Traditional ETL pipelines struggle with:
- Real-time synchronization gaps: Traditional etl jobs run on large dataset instead of incremental data and often scheduled at specific intervals making it difficult to support near-real time dashboards.
- Schema drift in semi-structured sources: The pipeline failed to support schema evolution with fields being added, removed or nested over time, which leads to broken jobs and needs a fix very often.
- Complex backfills during pipeline initialization: Setting up a new pipeline requires replaying of historical data, custom logic, large batch jobs and downtime.
- Data reliability: When data comes from multiple systems, inconsistencies and conflicting records often arise, creating multiple sources of truth and reducing trust in the data.
We needed a pipeline that could solve the problems.
Trivial solution
A common, but naive approach is to maintain additional datasets in Tableau or use federated queries to combine data from different systems. While this can provide a temporary view of unified data, it introduces several issues:
- Manual maintenance and reconciliation of datasets is error prone.
- Performance can suffer when querying across multiple sources.
- Data inconsistencies persist, and multiple sources of truth remain.
Final solution
We designed a delta lake based ingestion flow with medallion architecture:
1. Oracle & MongoDB → Kafka (CDC + Glue) : One-time load is done via AWS Glue jobs and dumped to s3 as delta. Incremental changes are captured with Debezium CDC connectors and written to kafka. We have setup a confluent kafka. We have glue job running on AWS. An ec2 instance is setup to run kafka-connect where the debezium connectors will be deployed.
Oracle debezium connector: https://gist.github.com/nabink-dev/3ad46ec38d41b7117933365836184319
MongoDB debezium connector: https://gist.github.com/nabink-dev/dd71101fcd90ad5fd67a7bf3010c4fd9
Note: One time load + cdc can also be done using debezium connectors. But since the oracle data size was huge, we have written a glue for one-time sync.
2. Kafka → S3 (Spark Streaming): This is a databricks job which used spark streaming to consume from kafka topics and appends raw data in Delta on s3.
Sample job:
https://gist.github.com/nabink-dev/30efe4b194ca50d9bef451fbce2c00c0
https://gist.github.com/nabink-dev/801a85b94ff6063b5280a12979e139ab
3. S3 → Databricks Delta Lake (Bronze): Create external delta tables in databricks unity catalog with s3 locations. This data has the initial load from glue and cdc data from kafka so is essentially scd type 2 data.
https://gist.github.com/nabink-dev/46da843ee7a0ce8237b0065fbdf99115
4. Bronze → Silver : Since mongodb is schema less unlike oracle, so we created a job to read the bronze tables and generate schema and store it in s3. Finally a continuous lakeflow declarative pipeline is triggered which reads the bronze tables, applies the schema, converts from scd type 2 to scd type 1 and save it as a streaming delta table in an intermediate silver layer in catalog.
Generate Schema: https://gist.github.com/nabink-dev/c8c2d86ab76f4e21eaa870fbe2412034#file-generate_schema-py
Create intermediate layer of silver: https://gist.github.com/nabink-dev/c8c2d86ab76f4e21eaa870fbe2412034#file-generate-silver-1-py
We then do our dimensional modelling to create dimension and fact tables. This serves our final silver layer.
Sample fact table: https://gist.github.com/nabink-dev/4d5b5246eadfd0af38e67abd9cc7a926
5. Silver → Gold : We then read the required silver tables, aggregate using our business logic to create the gold layer with KPIs for downstream analytics.
Sample gold table: https://gist.github.com/nabink-dev/6104f430f33a23aeda4a22f2634564fe
6. Final architecture diagram:
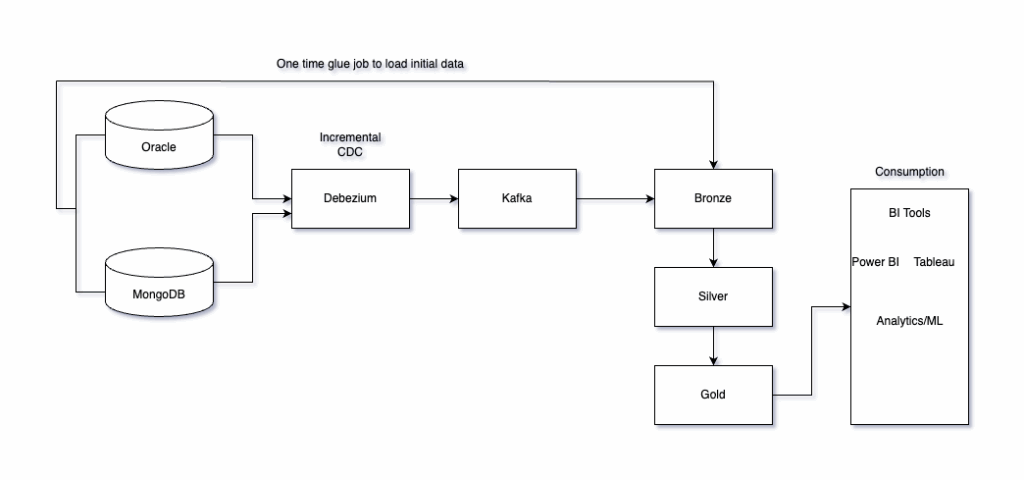
Conclusion
The final solution effectively tackles the identified problems by establishing a real-time, resilient, and reliable data pipeline. It solves real-time synchronization gaps by using Debezium CDC and Spark Streaming to ingest incremental data continuously, enabling near-real-time analytics.
For schema drift, especially from semi-structured sources like MongoDB, the approach generates and applies schemas within continuous pipelines (DLT), allowing for flexible schema evolution. Complex backfills are streamlined through an initial AWS Glue load combined with ongoing CDC, eliminating the need for extensive custom historical data processing.
Finally, data reliability is ensured by leveraging Delta Lake’s ACID properties, schema enforcement, and the progressive refinement of data through a Medallion Architecture (Bronze, Silver, Gold), establishing a single source of truth for downstream consumption.






