

P-hacking has been a persistent problem in scientific studies for decades, especially as the pressure to publish in academia continues to rise. Now, we’re seeing a very similar issue with AI benchmarking. In this article, I will explore what p-hacking is, why it happens despite scientists’ good intentions, and how it relates to the more modern problem of benchmark-hacking with LLMs.
What is p-value?
In short, it is an extension of the proof-by-contradiction argument into a probabilistic setting. Instead of saying a statement is true because assuming the opposite leads to a logical contradiction or implies that an impossible event has occurred, we say a statement is most likely true because assuming the opposite would force us to accept that a highly improbable event has occurred, that is, the observed result would be extremely unlikely if we assumed the negation of what we are trying to prove.
Let us say that Tom and Mary are playing a game of coin toss. They toss an unbiased coin, and the loser pays the winner five dollars. I agree that it is a very dumb and boring game, but bear with me. Mary notices that after playing three tosses, Tom has won twice. She suspects that the coin is biased in favor of Tom. Tom, of course, vehemently denies it and claims that he is just lucky.
Does Mary have a case? Well, if you think about it, that is the most balanced the results could have been — after three tosses, one of the players had to get at least two wins. Tom points this out, and they continue playing.
Now, after playing 30 times, Mary notices that Tom has won 20 times. Tom again denies any wrongdoing. The question is: does Mary have enough evidence to claim that Tom is cheating? Well, it depends — after all, it is not impossible for Tom to win all the games even with a completely unbiased coin. And we should stick to the principle of “innocent until proven otherwise” for any claims of cheating. But that cannot work in practice, because then cheating would never be caught. So, we use a probabilistic standard of evidence —
“Innocent until the probability of such a lopsided result from a fair game is at most p.”
Basically, we consider the result too lopsided in favor of Tom if the probability of getting such an extreme result — or even more extreme results — is too small to ever actually occur in practice. The probability is considered too small if it is at most p. This is also called the p-value, since statisticians are the most creative people when it comes to naming concepts.
Of course, if the threshold p is too large, we run the risk of convicting an innocent Tom of cheating; and if it is too small, Mary cannot have much of a shot at ever convicting Tom. The correct choice of p depends on the context of the claim. Most people in data analysis, psychology, or sociology use the threshold of p ≤ 0.05. Such a large value can have its own problems, but I will discuss that later.
For now, let’s come back to Mary’s accusation against Tom. With the definition settled, all Mary has to show is that Tom’s wins are too lopsided. What is the probability of Tom getting 20 or more wins out of 30 tosses? The probability of Tom winning exactly r times is \binom{30}{r}/2^{30}. So, the probability of getting the same or a more extreme result is —
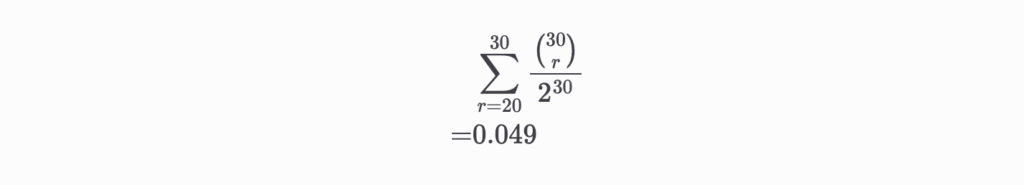
This is less than 0.05, so Mary indeed does have a case and has successfully demonstrated that Tom is cheating, but Tom, of course, still denies it and claims that 0.05 is too high a threshold.
Let us now look at Mary’s argument a little more closely. Mary’s claim is that Tom is cheating. This is what statisticians would call the alternate hypothesis. The standard belief is that Tom is innocent — this is what statisticians call the null hypothesis.
The argument is similar to proof-by-contradiction. In non-probabilistic logic, to prove that Tom is cheating, Mary must show that if we assume Tom to be innocent, the observed results would be impossible. In probabilistic logic, Mary instead only has to show that if we assume Tom to be innocent, the observed events would be extremely improbable (as opposed to impossible).
What is p-hacking?
Probabilities are delicate by nature — a slight change in conditions can change the probabilities a lot. To give you an idea, let’s assume that Tom and Mary play this tossing game every day and the coin is tossed exactly 30 times. Now, if Tom is honest and Mary is trying to find a reason to claim that Tom is cheating, how likely do you think it is that there would be a day when Tom gets at least 20 wins? If she keeps trying, this is bound to happen eventually. Then she can write about this incident.
It is not uncommon for data analysts to inadvertently use a similar technique to find patterns that look statistically significant when, in fact, there is no real pattern at all. If an analyst gets a dataset and tries 20 arbitrary models on a dataset that does not have any pattern, there is still a probability of 1-0.95^{20}=0.64 of getting a pattern that would be inside the 0.05 threshold for the p-value. To avoid this, there must be a test dataset that has been held out and can be used exactly once to check the model’s p-value. But this is almost never done, because you can’t simply throw away data after trying every model that you have generated.
It is actually very difficult to avoid p-hacking even with the best intentions, because publication culture is biased toward successful results. You get published only if you show a statistically significant finding. That, of course, means that if you keep running different experiments, you will publish only when your calculated p-value is small enough. But that calculation assumes that each experiment is independent of the others and that no additional experiments are considered when computing the p-value of any single experiment.
However, the researcher is trying multiple theories and publishing whenever one of the calculations yields a small-enough p-value. Since the p-value is never zero, by the law of large numbers such a low-probability event will eventually occur — and then get published as a significant result. This problem is particularly severe in fields that accept a relatively high p-value, like 5%.
The result is that scientific literature becomes riddled with findings that appear true but are actually false positives. Of course, science eventually tries to correct this through systematic studies or meta-analyses that consider effects replicated by many researchers.
On the origin of LLMs by means of benchmark selection
Charles Darwin shook the world with his book On the Origin of Species by Means of Natural Selection, where he showed that even under random variation, a consistent selection pressure would shape organisms to fit their environment because the ones that were less fit would not survive. This is also the mechanism behind how LLMs get published: LLMs are selected by a similar process, except that instead of natural selection, the selection pressure is the scores on public benchmarks.
This might have been fine if the benchmarks were actually random samples drawn from real-world problems to be solved. The problem is that we do not know what kind of benchmark can truly reflect real-world cases, and, moreover, benchmarks are static rather than continually sampled from real-world tasks. Let me explain in details –
Benchmarks are surrogates
The benchmarks hardly ever test the real-world use cases of LLMs. They are mostly arbitrary tests that humans assume only intelligent humans would be able to perform, and therefore treat as tests of intelligence for LLMs. But we have seen in many cases that LLMs can pass these extremely difficult tasks while failing at basic tasks or reasoning that seem trivial to humans. The reason this happens is that we have a good understanding of human failure modes—both because we are constantly exposed to other humans and because we can introspect about ourselves.
Intelligence is not a one-dimensional trait; it is multi-faceted, and we often don’t think about testing abilities that humans perform effortlessly. However, when we select which LLMs to publish or pursue, we rely on these benchmarks to guide that selection. This means we are selecting for the wrong things, and it may result in a degradation of real-world performance.
Benchmarks are static
The other, and arguably more insidious, problem is that benchmarks are by nature static. Even if they were sampled from the distribution of real-world tasks, any finite benchmark cannot on its own reflect all real-world scenarios. This results in LLMs being optimized—through selection pressure—for certain things while being compromised on the aspects that the benchmarks fail to capture.
Conclusion
These two reasons explain why AI coding software has not improved significantly, even though LLMs show consistent performance gains on benchmarks. While it is true that the tooling around LLMs has improved substantially over the last year, the core capability of coding—and the quality of the generated code—has not improved much, and the failure modes remain essentially the same. I would even go so far as to say that even if LLMs reach superhuman benchmark performance, AI coding agents would still lag behind humans in real-world coding work, because the benchmarks are merely surrogate tests and are themselves static.









