What is batch computing?
Batch computing means running jobs asynchronously and automatically, across one or more computers.
What is AWS Batch Job?
AWS Batch enables developers to easily and efficiently run hundreds of thousands of batch computing jobs on AWS. AWS Batch dynamically provisions the optimal quantity and type of compute resources (for example, CPU or memory optimized instances) based on the volume and specific resource requirements of the batch jobs submitted. AWS Batch plans, schedules, and executes your batch computing workloads across the full range of AWS compute services and features, such as Amazon EC2 and Spot Instances.
Why use AWS Batch Job ?
- Fully managed infrastructure – No software to install or servers to manage. AWS Batch provisions, manages, and scales your infrastructure.
- Integrated with AWS – Natively integrated with the AWS Platform, AWS Batch jobs can easily and securely interact with services such as Amazon S3, DynamoDB, and Recognition.
- Cost-optimized Resource Provisioning – AWS Batch automatically provisions compute resources tailored to the needs of your jobs using Amazon EC2 and EC2 Spot.
AWS Batch Concepts
- Jobs
- Job Definitions
- Job Queue
- Compute Environments
Jobs
Jobs are the unit of work executed by AWS Batch as containerized applications running on Amazon EC2. Containerized jobs can reference a container image, command, and parameters or users can simply provide a .zip containing their application and AWS will run it on a default Amazon Linux container.
| $ aws batch submit-job –job-name poller –job-definition poller-def –job-queue poller-queue |
Job Dependencies
Jobs can express a dependency on the successful completion of other jobs or specific elements of an array job.
Use your preferred workflow engine and language to submit jobs. Flow-based systems simply submit jobs serially, while DAG-based systems submit many jobs at once, identifying inter-job dependencies.
Jobs run in approximately the same order in which they are submitted as long as all dependencies on other jobs have been met.
| $ aws batch submit-job –depends-on 606b3ad1-aa31-48d8-92ec-f154bfc8215f … |
Job Definitions
Similar to ECS Task Definitions, AWS Batch Job Definitions specify how jobs are to be run. While each job must reference a job definition, many parameters can be overridden.
Some of the attributes specified in a job definition are:
- IAM role associated with the job
- vCPU and memory requirements
- Mount points
- Container properties
- Environment variables
| $ aws batch register-job-definition –job-definition-name gatk –container-properties … |
Job Queues
Jobs are submitted to a Job Queue, where they reside until they are able to be scheduled to a compute resource. Information related to completed jobs persists in the queue for 24 hours.
| $ aws batch create-job-queue –job-queue-name genomics –priority 500 –compute-environment-order … |
Compute Environments
Job queues are mapped to one or more Compute Environments containing the EC2 instances that are used to run containerized batch jobs.
Managed (Recommended) compute environments enable you to describe your business requirements (instance types, min/max/desired vCPUs, and EC2 Spot bid as x % of On-Demand) and AWS launches and scale resources on your behalf.
We can choose specific instance types (e.g. c4.8xlarge), instance families (e.g. C4, M4, R3), or simply choose “optimal” and AWS Batch will launch appropriately sized instances from AWS more-modern instance families.
Alternatively, we can launch and manage our own resources within an Unmanaged compute environment. Your instances need to include the ECS agent and run supported versions of Linux and Docker.
| $ aws batch create-compute-environment –compute- environment-name unmanagedce –type UNMANAGED … |
AWS Batch will then create an Amazon ECS cluster which can accept the instances we launch. Jobs can be scheduled to your Compute Environment as soon as the instances are healthy and register with the ECS Agent.
Job States
Jobs submitted to a queue can have the following states:
- SUBMITTED: Accepted into the queue, but not yet evaluated for execution
- PENDING: The job has dependencies on other jobs which have not yet completed
- RUNNABLE: The job has been evaluated by the scheduler and is ready to run
- STARTING: The job is in the process of being scheduled to a compute resource
- RUNNING: The job is currently running
- SUCCEEDED: The job has finished with exit code 0
- FAILED: The job finished with a non-zero exit code or was cancelled or terminated.
AWS Batch Actions
- Jobs: SubmitJob, ListJobs, DescribeJobs, CancelJob, TerminateJob
- Job Definitions: RegisterJobDefinition, DescribeJobDefinitions, DeregisterJobDefinition
- Job Queues: CreateJobQueue, DescribeJobQueues, UpdateJobQueue, DeleteJobQueue
- Compute Environments: CreateComputeEnvironment, DescribeComputeEnvironments, UpdateComputeEnvironment, DeleteComputeEnvironment
AWS Batch Pricing
There is no charge for AWS Batch. We only pay for the underlying resources we have consumed.
Use Case
Poller and Processor Service
Purpose
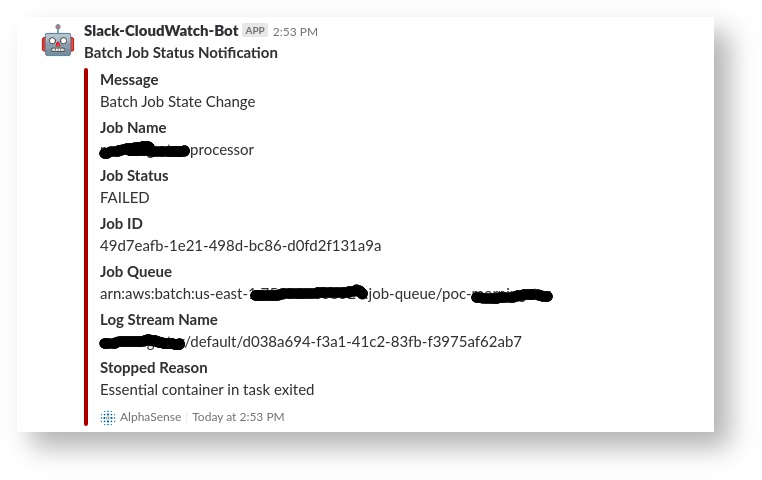
Poller service needs to be run every hour like a cron job which submits one or more requests to a processor service which has to launch the required number of EC2 resource, process files in parallel and terminate them when done.
Solution
We plan to go with Serverless Architecture approach instead of using the traditional beanstalk/EC2 instance, as we don’t want to maintain and keep running EC2 server instance 24/7.
This approach will reduce our AWS billing cost as the EC2 instance launches when the job is submitted to Batch Job and terminates when the job execution is completed.
Poller Service Architecture Diagram
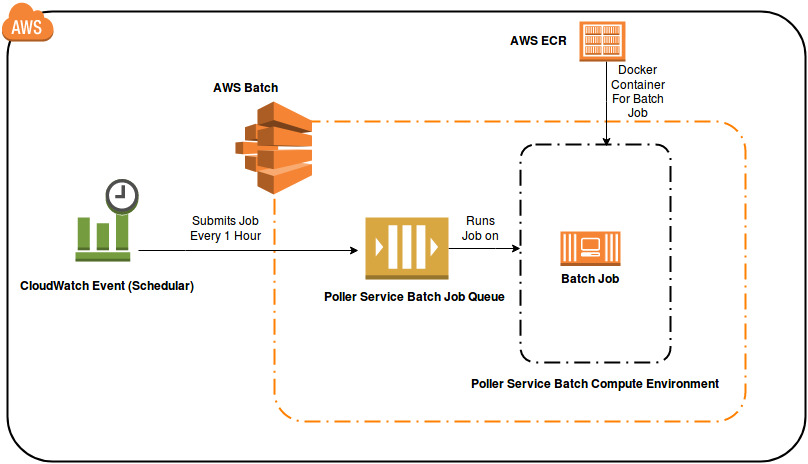
Processor Service Architecture Diagram
First time release
For Poller and Processor Service:
- Create Compute environment
- Create Job queue
- Create Job definition
To automate above resource creation process, we use batchbeagle (for Installaion and configuration, please refer batch-deploymnent repository)
Command to Create/Update Batch Job Resources of a Stack (Creates all Job Descriptions, Job Queues and Compute Environments)
| beagle -f stack/stackname/servicename.yml assemble |
To start Poller service:
- Enable a Scheduler using AWS CloudWatch rule to trigger poller service batch job.
Incremental release
We must create a new revision of existing Job definition environment which will point to the new release version tagged ECR image to be deployed.
Command to deploy new release version of Docker image to Batch Job (Creates a new revision of an existing Job Definition)
| beagle -f stack/stackname/servicename.yml job update job-definition-name |
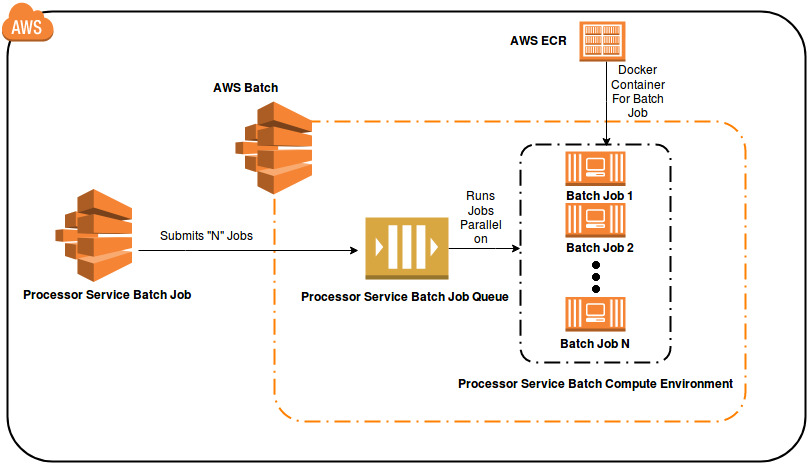
Monitoring
We will use AWS Batch event stream for CloudWatch Events to receive near real-time notifications regarding the current state of jobs that have been submitted to your job queues.
AWS Batch sends job status change events to CloudWatch Events. AWS Batch tracks the state of your jobs. If a previously submitted job’s status changes, an event is triggered. For example, if a job in the RUNNING status moves to the FAILED status.
We will configure an Amazon SNS topic to serve as an event target which sends notification to lambda function which will then filter out relevant content from the SNS message (json) content and beautify it and send to the respective Environment slack channel .
CloudWatch Event Rule → SNS Topic → Lambda Function → Slack Channel
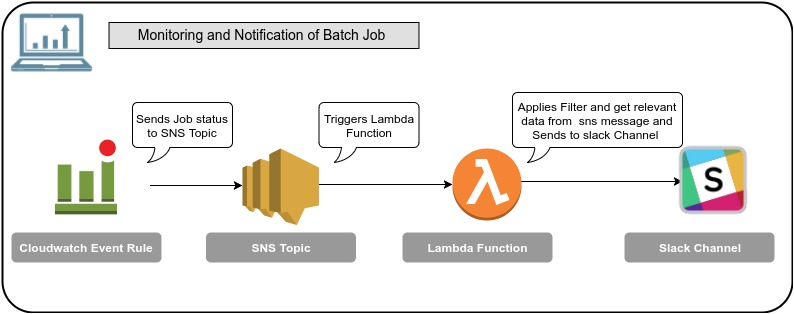
Batch Job Status Notification in Slack
Slack notification provides the following details:
- Job name
- Job Status
- Job ID
- Job Queue Name
- Log Stream Name