

Firebase ML Kit Introduction
At Google I/O 2018, Google announced Firebase ML Kit, a part of the Firebase suite that intends to give our apps the ability to support intelligent features with more ease. The SDK currently comes with a collection of pre-defined capabilities that are commonly required in applications. Firebase ML Kit offers machine learning capabilities underneath a form of a wrapper, it also offers their capabilities inside of a single SDK.
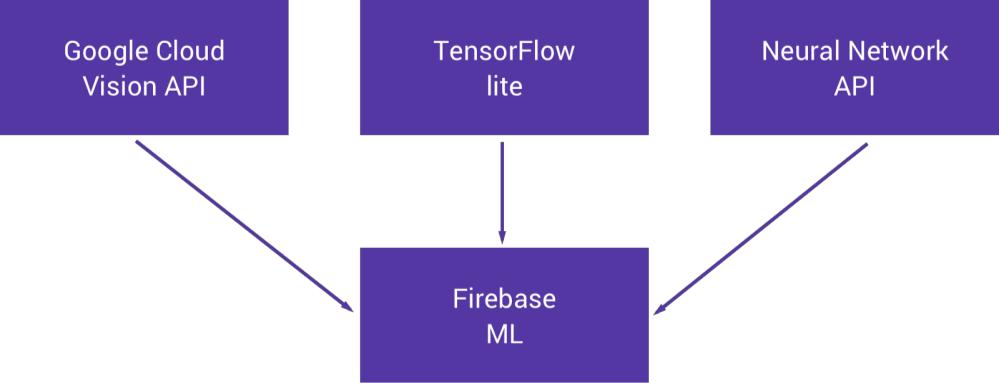
Currently ML Kit offers the ability to:
- Recognize text
- Recognize landmarks
- Face detection
- Scan barcodes
- Label images
Objective
Recognizing text in images, such as the text of a street sign, and recognizing the text of documents.
Recognize Text in Images with Firebase ML Kit
ML Kit has both a general-purpose API suitable for recognizing text in images, such as the text of a street sign and an API optimized for recognizing the text of documents. The general-purpose API has both on-device and cloud-based models. Document text recognition is available only as a cloud-based model.
Prerequisites
Before you proceed, make sure you have access to the following:
- the latest version of Android Studio
- a device or emulator running Android API level 21 or higher
- a Google account for Firebase and Google Cloud
Create a Firebase Project
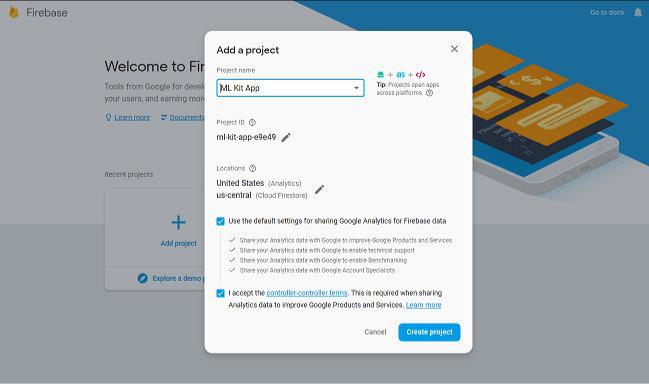
To enable Firebase services for your app, you must create a Firebase project for it. So log in to the Firebase console and, on the welcome screen, press the Add project button. In the dialog that pops up, give the project a name and press the Create project button.
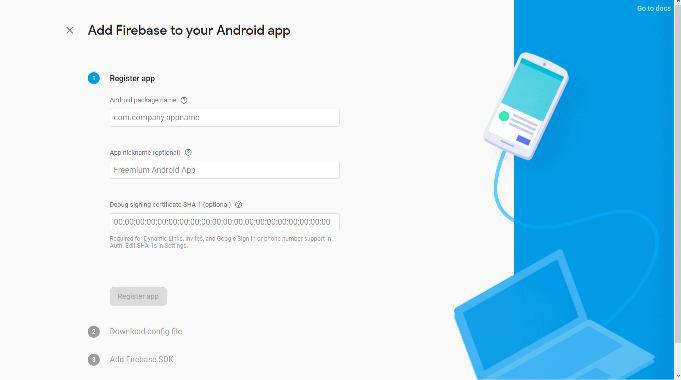
From the overview screen of your new project, click Add Firebase to your Android app. Enter package name and other information and press the Register app button. Now downloads configuration file ( google-services.json) that contains all the necessary Firebase metadata for your app.
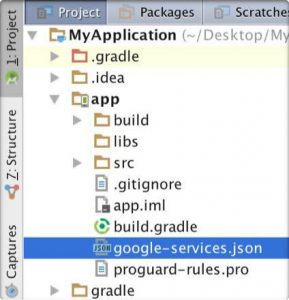
Configure Your Android Studio Project
- Switch to the Project view in Android Studio to see your project root directory. Move the google-services.json file you just downloaded into your Android app module root directory

- Modify your project level build.gradle files to use Firebase.
- Add dependencies in app-level build.gradle:
- Finally, press “Sync now”.
- Add permissions in AndroidManifest.xml
On Device Text Recognition
To recognize text in an image, create a FirebaseVisionImage object from either a Bitmap, media.Image, ByteBuffer, byte array, or a file on the device. Then, pass the FirebaseVisionImage object to the FirebaseVisionTextRecognizer’s processImage method. If the text recognition operation succeeds, a FirebaseVisionText object will be passed to the success listener. A FirebaseVisionText object contains the full text recognized in the image and zero or more TextBlock objects. Each TextBlock represents a rectangular block of text, which contains zero or more Line objects. Each Line object contains zero or more Element objects, which represent words and word-like entities (dates, numbers, and so on).
https://gist.github.com/ingenious3/bc2529e585c701d4ddbef6274498575e#file-mainactivity-java
Demo: https://drive.google.com/openid=1XEgRMyGbQEprvM3F8h9jGrLOPyRvAZpB
On Cloud Text Recognition
If you want to use the Cloud-based model, and you have not already enabled the Cloud-based APIs for your project, do so now. Navigate to ML Kit section of the Firebase console. If you have not already upgraded your project to a Blaze plan, click Upgrade to do so. Only Blaze-level projects can use Cloud-based APIs. If Cloud-based APIs aren’t already enabled, click Enable Cloud-based APIs.
The document text recognition API provides an interface that is intended to be more convenient for working with images of documents on the cloud. To recognize text in an image, create a FirebaseVisionImage object from either a Bitmap, media.Image, ByteBuffer, byte array, or a file on the device. Then, pass FirebaseVisionImage object to FirebaseVisionDocumentTextRecognizer’s processImage method. If the text recognition operation succeeds, it will return a FirebaseVisionDocumentText object. A FirebaseVisionDocumentText object contains the full text recognized in the image and a hierarchy of objects (blocks, paragraph, word, symbol) that reflect the structure of the recognized document.
Demo: https://drive.google.com/openid=1qIfLKV3Mz4MJDHUf5A17uT_0c1KWz_hK
Stay tuned for my next article.









