

In this blog, We will be covering the following topics and try to give an introduction about Kubernetes (K8s), which is an open-source system for automating deployment, scaling, and management of containerized applications.
- Why is Container orchestration needed?
- Why Kubernetes?
- K8s Architecture
- Master Node Components
- Worker Node Components
Why is Container orchestration needed?
- Manages container lifecycle within the cluster.
- Provisioning and deployment of containers.
- Redundancy and availability of containers.
- Scaling up or removing containers to spread application load evenly across host infrastructure.
- Movement of containers from one host to another if there is a shortage of resources in a host, or if a host dies.
- Allocation of resources between containers.
- External exposure of services running in a container with the outside world.
- Load balancing of service discovery between containers.
- Health monitoring of containers and hosts.
What is Kubernetes?
Kubernetes is an open-source orchestration system for containers. It handles scheduling onto nodes in a compute cluster and actively manages workloads to ensure that their state matches the users’ declared intentions.
Why Kubernetes?
Service discovery and load balancing
Kubernetes gives Pods their IP addresses and a single DNS name for a set of Pods and can load-balance across them.
Storage orchestration
Automatically mount the storage system of your choice, whether from local storage, a public cloud provider such as GCP or AWS, or a network storage system such as NFS, iSCSI, Gluster, Ceph, Cinder, or Flocker.
Automated rollouts and rollbacks
Kubernetes progressively rolls out changes to your application or its configuration, while monitoring application health to ensure it doesn’t kill all your instances at the same time. If something goes wrong, Kubernetes will rollback the change for you.
Automatic bin packing
Automatically places containers based on their resource requirements and other constraints, while not sacrificing availability.
Self-healing
Restarts containers that fail, replaces and reschedules containers when nodes die, kills containers that don’t respond to your user-defined health check, and doesn’t advertise them to clients until they are ready to serve.
Secret and configuration management
Deploy and update secrets and application configuration without rebuilding your image and without exposing secrets in your stack configuration.
Batch execution
In addition to services, Kubernetes can manage your batch and CI workloads, replacing containers that fail, if desired.
Horizontal scaling
Kubernetes autoscaling automatically sizes a deployment’s number of Pods based on the usage of specified resources (within defined limits – eg CPU % usage).
Rolling updates
Updates to a Kubernetes deployment are orchestrated in “rolling fashion,” across the deployment’s Pods. These rolling updates are orchestrated while working with optional predefined limits on the number of Pods that can be unavailable and the number of spare Pods that may exist temporarily.
Canary deployments
A useful pattern when deploying a new version of a deployment is to first test the new deployment in production, in parallel with the previous version, and scale up the new deployment while simultaneously scaling down the previous deployment.
Visibility
Identify completed, in-process, and failing deployments with status querying capabilities.
Time savings
Pause a deployment at any time and resume it later.
Version control
Update deployed Pods using newer versions of application images and roll back to an earlier deployment if the current version is not stable.
Kubernetes Architecture
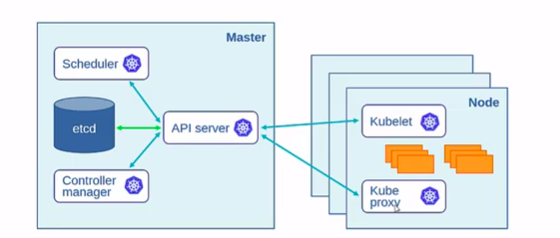
In Kubernetes architecture,
You can have one master – multi worker node, multi-master – multi worker node or even everything on a single node for testing purpose.
You can see different components on master as shown in the above diagram
On Master node,
The API server is that main component, as everything in Kubernetes cluster will connect and talk to this API server.
Other components are a scheduler, controller manager we call them as Kubernetes control plane.
And the ETCD component is for storing the information of Kubernetes cluster, if we lose ETCD we lose the whole data of the cluster.
We can also configure it externally, but in the most common scenario, we deploy it along the Kubernetes control plane.
On Worker node,
Kubelet is the main component because the Kubelet is going to talk to the API server which gives the status of the node, app running inside that node.
And we also have Kube-proxy which also communicates to API server, which does traffic redirection using Ip tables by default.
K8 Architecture Components
Master Node Components
Master nodes have the following components as shown
1) API Server
2) Scheduler
3) Controllers
4) ETCD
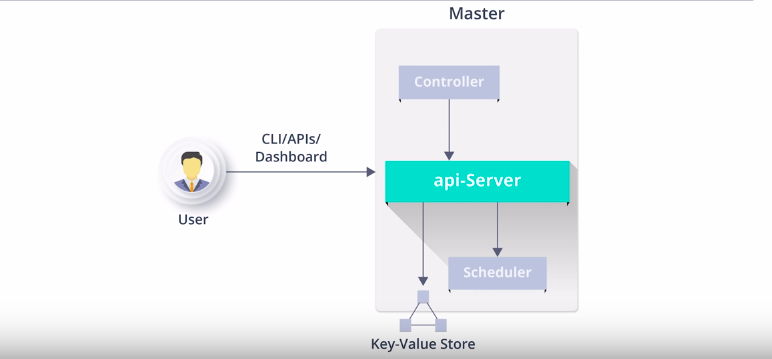
Before we begin,
Everything in k8s is objects same as like everything in Linux is a file , Object is a persistent entity in kubernetes . One of the objects is Pod, Pod is a logical collection of one or more containers which are always scheduled together.
So starting with API-server
1) All the administrative tasks are performed via API server within the master node
2) A user sends an API request to api server which then authenticates, validates and processes the request, after executing the request the resulting state of the cluster is stored in the distributed key-value store.
Let’s discuss in detail about it,
Master Node Components – API Server
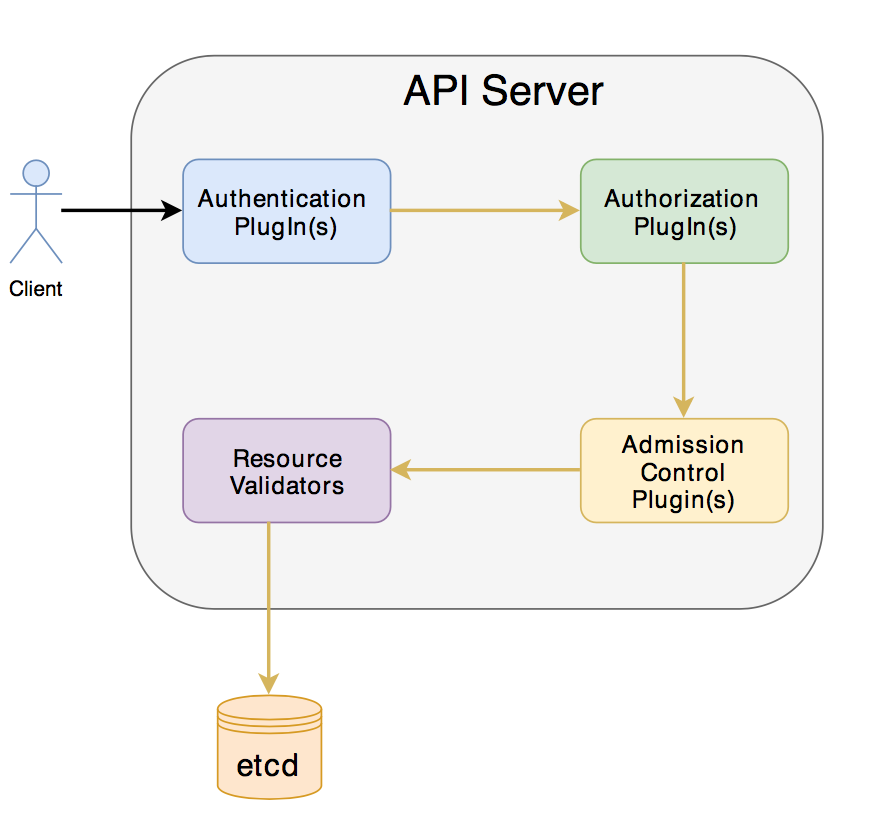
1) The client for the API Server can be either Kubectl(command-line tool) or a Rest API client.
2) As mentioned in the diagram, there are several plugin’s that are invoked by Api Server before creating/deleting/updating the object in ETCD.
3) When we send a request for object creation operation to Api Server, it needs to authenticate the client. This is performed by one or more authentication plugins. The authentication mechanism can be based on the client’s certificate or based on Basic authentication using HTTP header “Authorization”.
4) Once the authentication is passed by any of the plugins, it will be passed to Authorization plugins. It validates whether the user has access to perform the requested action on the object. Examples are like developers are not supposed to handle cluster role bindings or security policies. They are supposed to be controlled at the cluster level only by the DevOps team. Once the authorisation passes the request will be sent to Admission Control PlugIns(ACP).
5) Admission Control PlugIns are responsible for initialising any missing fields or default values. For example, if we didn’t specify any required parameter information in the object creation, one of the plugIns will take care about adding default that parameter to the resource specification.
6) Finally, API Server validates the object by checking the syntax and object definition format and stores it in ETCD.
Master Node Components – Scheduler
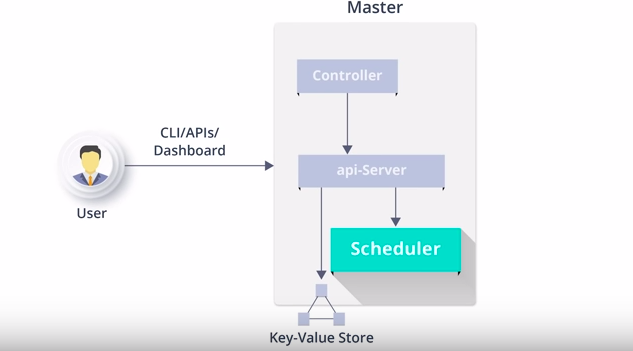
1) So as the name suggests scheduler schedules the object to different worker nodes
2) It registers with Api Server for any newly created object/resource.
3) The scheduler has the resource information of each worker nodes and also knows the constraints the user might have set.
4) Before scheduling, It checks whether the worker node has the desired capacity or not
5) Its also takes into account various user parameters, eg any specific volumes like SSD
So basically it watches for newly created pods that have no node assigned and selects a node for them to run on it.
The next component we have is the controller manager
Master Node Components – Controller
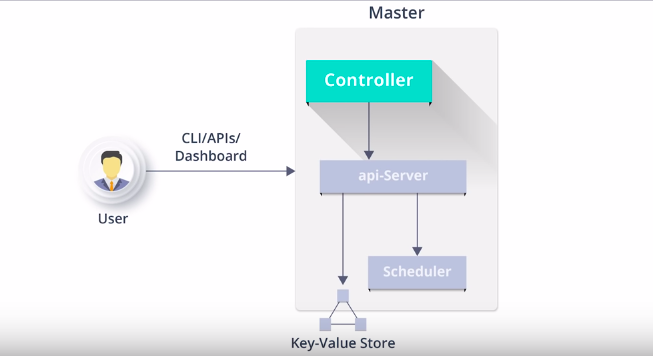
1) It manages different non-terminating control loops which regulate the state of Kubernetes cluster.
2) Now each one of this control loop knows about their desired state of the objects it manages, and then they watch their current state through API server. Now In the current loop if the current state of the object that manages does not meet the desired state, then the control loop itself takes the corrective steps to make sure that the current state is the same as the desired state.
So basically it makes sure that your current state is the same as the desired state, as specified in the resource specification
3) There are multiple objects in k8s, to manage these objects we have different controllers available under controller manager.
4) All controllers watch the API Server for changes to resources/objects and perform necessary actions like create/update/delete of the resource.
Master Node Components – ETCD
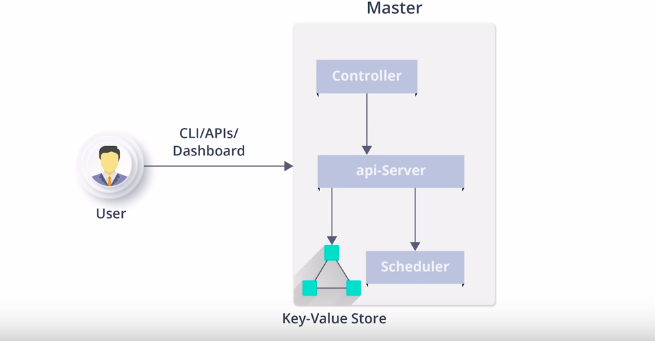
After that last component that we have is ETCD
1) So as I have mentioned earlier ETCD is distributed key-value store which is used to store the cluster state, So either it has to be the part of Kubernetes master or you can configure it externally in cluster mode.
2) It is written in the Go programming language.
3) Besides storing the cluster state, it is also used to store config details.
So now let’s move on to worker node components
Worker Node
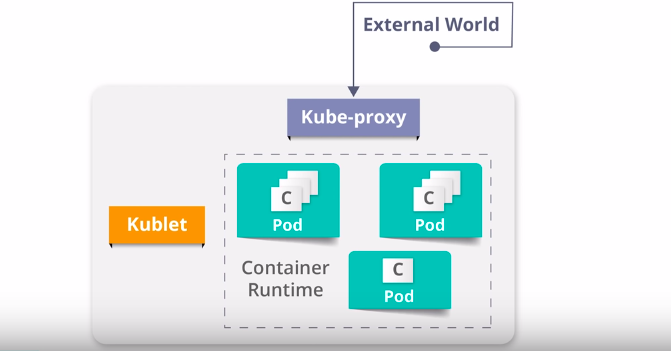
A worker node can be a machine, VM or any physical server which runs the app (pods) and is controlled by the master node.
To access the app from the external world, we have to connect to the worker node and not to the master node
So as I have brief you about the worker node, let’s discuss various components of the worker node
Worker node has mainly three components – Kubelet, Kube-proxy and container runtime
Worker Node Components -container runtime
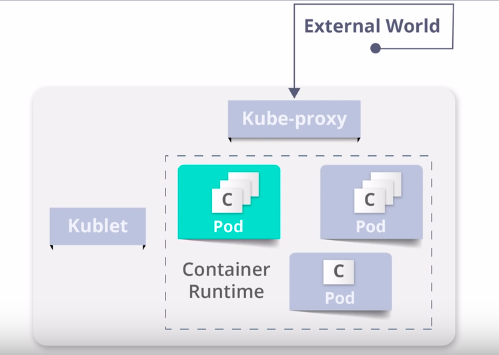
Container runtime is basically used to run and manage the containers life cycle on the worker node. For example, docker, RKT, containers, and LX, DETC, K8s supports most of them.
Docker is widely used in the container world.
Now you have understood what Container runtime is let’s move to the next component
Worker Node Components -Kubelet
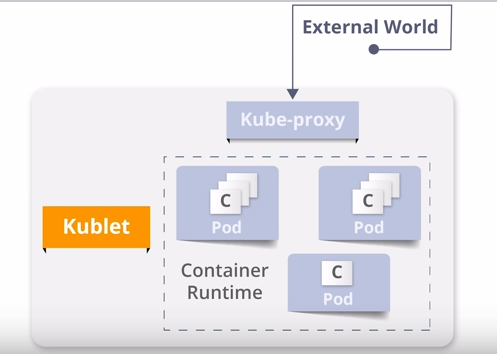
1) It is basically an agent which runs on each worker node and communicates with the master node via the API server
So if we have ten worker nodes, then Kubelet runs on every worker node.
2) It receives the pod definition via various means and runs the containers associated with that pod by instructing to container runtime.
3) It will also do health checks for the containers and restart if needed.
4) It monitors the status of running containers and reports to API server about status, events and resource consumption.
5) It connects to the container runtime using the container runtime interface which consists of various protocol buffer, GRPC APIs and libraries
Now let’s move on to the 3rd component
Worker Node Components -Kubeproxy
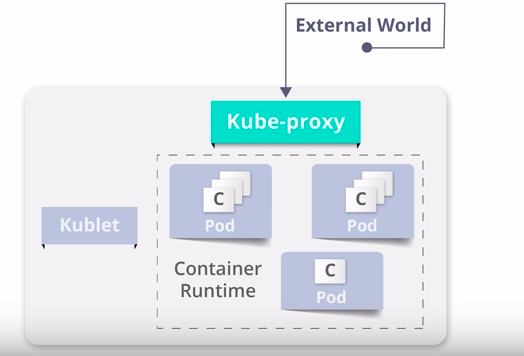
1) It is a network proxy which runs on each worker node, and they listen to the API server for each service point creation or deletion.
So basically it helps you to access your application on localhost by mapping the IP address and port forwarding the port on which your application is running.
2) So for each service point, Kube proxy sets the route so that it can reach it.
Kubernetes WorkFlow
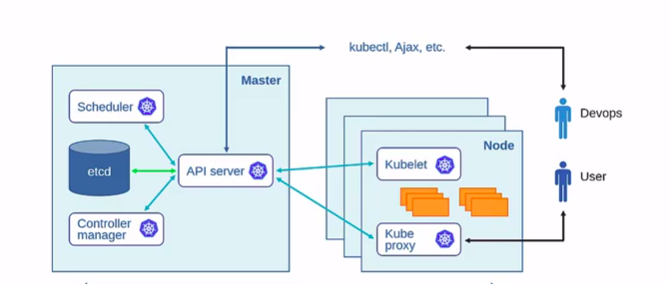
DevOps/infra – Wants to deploy an app via Kubectl/API
The workflow will be as follows
1) Kubectl/API will talk to API -server
2) API-server stores the request in ETCD, then it will talk to the scheduler
3) Scheduler will choose one node to schedule the app
4) Then API server will then talk to Kubelet
5) Kubelet will talk to container runtime (e.g. docker) which will deploy the app
6) Kubelet will report it back to API server whether it succeeded or not and API server will store its status to ETCD
7) Kube proxy will get notified about the new app, and through Kubelet it will come to know local IP, ports of the app
Developer/user – Will access application on local machine using Kubelet port-forward via Kube proxy
Still, a lot to cover, Right ??
K8s is like an ocean to cover. We will try to cover up the remaining part in our next upcoming blog.




