
Introduction
Just A Rather Very Intelligent System, or as many of us know as the J.A.R.V.I.S., was the operating system Iron Man had, before Ultron attacks it and Tony Stark had to create FRIDAY. However overlooking the amazing UI/UX of JARVIS, one thing which still stands out about JARVIS is how it is able to collect and connect all the information. This abstraction of the world data, or more technically the abstraction of the documents and application layer involved in the exchange of information, has been a gift of the Web 3.0.
Evolution of the internet
Web 1.0, or as we know it the Internet, was the first stage of the beginning of a new era of sharing of information. The main characteristics in it was rendering static web content documents and interconnecting them via hyperlinks, which in itself was a huge jump over documents being stored at various places with heavy constraints pertaining to connecting the sparsely spread document archives. Web 2.0 came much later with the advent of social media and user based dynamic content development across the world. However with the user based dynamic content development, again came the issue of connecting information on various archives or sites, due to the unconstrained nature of the contents. This and some other developments in the field of computing systems brought in a need for another revolution in the field of internet.

Fig 1: The Internet (Courtesy: http://kingofwallpapers.com/internet/internet-006.jpg)
Enter Web 3.0, or as is also recognized as the Semantic Web, the Linked Data Web, or even the Web of Data. This new school of evolution brought in an abstraction of the application layer itself. Anything which is generated in an unconstrained text document format, was expected not only to be read or understood by another human being, but also should have some sort of intelligence/format so as to generate and update links to other documents or information. A very naive example which could be cited here is, let’s say on a particular day whenever we update a status on one of the social media sites, and then move on to another site and realize that this site “knows” about the state of mind we are in, and thus suggests a product, may be a song, or a gift. Now one integral concept which should be bore in mind is that the structure of the document should not be the deterrent to the spread of information.
Semantic Web
All good in theory, but the immediate next question which pops up in mind is, how? How can we connect two or more different unconstrained, probably unstructured, free text documents and stitch them together to form a collection of information? To help facilitate this, a concept of “Semantic Web” is employed, which tries to understand the intent of a document and then find out other “semantically” connected documents. In more technical terms, the system tries to figure out the key areas in the document, and then connect them to other documents which are in close relations with the document in question.
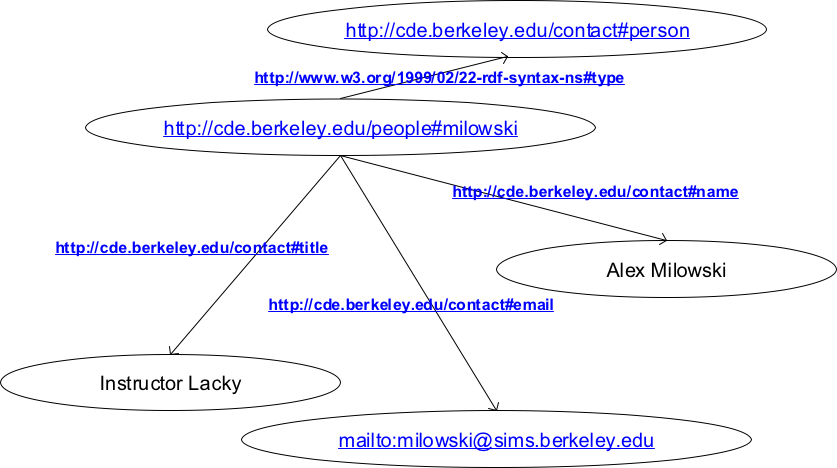
Fig2: An illustrative semantic web. (Courtesy: http://courses.ischool.berkeley.edu/i290-14/s05/lecture-27/rdf-graph.png)
Now in order to achieve such a feat W3C has listed down some standardized formats or schema in accordance with the semantic web, in which all of this can achieved.
Some of the standardized concepts or procedures are listed as below,
- Parts of Speech (POS) tagging: As might already be obvious, there is a need for Natural Language Processing, or NLP, before we can do any sort of analysis on the free text. There are quite a few generalized models like the Stanford CoreNLP or the OpenNLP, which can be employed to ease the process, like the parts of speech(pos) tagging, and various other analysis of the free text. After the POS tagging the various nouns, especially proper nouns, are used as linkage entities to connect to other documents which contain texts of similar concepts. Same can be done for the other POS tags, viz. verbs, adverbs, etc.
- Resource Description Framework (RDF): RDF is the data modeling language which is used to store all information and be represented in for the Semantic Web. This is basically a triple store, in which two concepts or entities are linked together by some designated relationship. These relationships, in themselves can again be related to some other concepts or relationships with some low level relationship between them. This creates a graph network of entities or relationships with other entities or relationships, which is also known as the Semantic Network or the Knowledge Graph. There are a few resources over the web which render semantic networks with an ease of access, viz. DBPedia, YAGO, FreeBase.
- SPARQL (SPARQL Protocol and RDF Query Language): This is the query language which is used on top of RDF or the semantic network to help facilitate traversal through the various concepts and relations. It is specifically designed to query data across various systems, and fetch results for records stored as triples, as explained above. Some libraries like the Apache Jena, Twinkle, etc., provide APIs so as to query the RDFs with a lot of abstraction on the query generation process.
- Ontology: The schema of the language or knowledge representation (KR) language, in which the RDF or the Semantic Web is to be parsed or understood, is called an Ontology. In very naive terms the definition of the format of the knowledge graph is known as an Ontology. It contains information regarding the various components used while defining an ontology. A very commonly used ontology is the Web Ontology Language, or OWL. The design or the schema of the OWL enables you to define concepts in a very dynamic fashion and hence retaining the much desired flexibility of the RDF. These concepts can be reused as much and as often as possible, because of the way it is defined, so that it can be selected and assembled in various combinations with other concepts as needed for many various applications.
Current state of affairs
As it is the current state of semantic web is pretty advanced, and is currently used in numerous technological solutions. Libraries and plugins for various document based storage, like the ElasticSearch or SolR, have been developed and are currently used to further enhance the capabilities of the knowledge graph. I am pretty sure we all have heard of or watched the famous IBM Watson in Jeopardy. There are numerous researches which are currently underway using this concept of creation of knowledge graph and creating solutions to problems which were previously not possible.








