Technologies in the Graph Space
Graph Database System (OLTP)
Technologies that provide online transactional processing (OLTP) capabilities for graph fall under this category. It is a system with Create, Read, Update and Delete (CRUD) methods that can be applied real-time on a graph data model. In contrast to index-intensive[1], set theoretic operations of relational databases, these technologies make use of index-free, local traversals which means joins are of constant time. They are optimized for high-speed graph traversals. Examples are: neo4j, OrientDB etc.
Graph Compute Engines (OLAP)
Technologies that provide offline graph processing capabilities primary used for graph analytics. They enable graph computations algorithms to be run on very large datasets optimized for batch processing and online analytic processing (OLAP). They are agnostic of the underlying storage system, which can be a relational database, graph database or a flat file. Examples are: Apache Giraph, Pegaus.
Types Of Graph
Property Graph
As the name suggests a property graph can attach properties to the graph’s entities – Node & Links/Edges. It has the following characteristics:
1. Contains nodes and relationships.
2. Nodes contains properties (key-value pairs)
3. Relationships are named and directed and always have a start and end node. There isn’t any dangling relationship.
4. Relationships also have properties.
It is entity centric and suits well for rapid traversals between nodes.
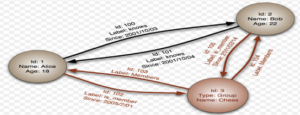
Figure 1: Sample property graph
When to use?
Property graphs can be seen as relational databases, with rows replaced by graph nodes and foreign keys replaced by graph edges. Each row in the relational table becomes a node in the graph and column values become properties of the node. Foreign keys in relational tables do not have any properties and the link is generic at table level while in a property graph links can have properties and link is at entity (row) level.
Two significant advantages of graph approach:
1) Joins are expensive due to relational databases being implemented on set theory[2] The performance benefits of graph databases are visible for a complex query with multiple joins. For an application that demands a lot of recursive processing (multi staged self joins), for example finding friends of friends OR querying an org chart with multiple hierarchies, data modeling in graph makes a lot of sense.
Execution time (in seconds) for multiple join queries comparison between Graph database and relational database for 1000 users.
|
Depth
|
SQL Join
|
Graph traversal
|
Record returned
|
|
2
|
0.028
|
0.04
|
~900
|
|
3
|
0.213
|
0.06
|
~999
|
|
4
|
10.273
|
0.07
|
~999
|
|
5
|
92,613.50
|
0.07
|
~999
|
Execution time (in seconds) for multiple join queries comparison between Graph database and relational database for 1 million users.
|
Depth
|
SQL Join
|
Graph traversal
|
Record returned
|
|
2
|
0.016
|
0.01
|
~2500
|
|
3
|
30.267
|
0.168
|
~125,000
|
|
4
|
1543.505
|
1.359
|
~600,000
|
|
5
|
Not finished
|
2.132
|
~800,000
|
The above comparison is for executing a query to find friend of a friend. As can be seen from the above comparison switch to graph database can be made when the application demands querying on related data at depth level more than 3.
More flexible data model in terms of expressing relations. This helps to formulate queries based on relations at run time rather than at design time and also rank relations. For e.g. consider the below schema
Person:
|
Id
|
Name
|
|
1
|
Ram
|
|
2
|
Shyam
|
Book:
|
Id
|
Name
|
|
1
|
Graph database
|
|
2
|
Harry Potter
|
Comments:
|
Person_id
|
book_id
|
comment
|
|
1
|
1
|
Nice book
|
|
1
|
2
|
Harry is awesome
|
|
2
|
1
|
Graph rocks
|
|
2
|
2
|
Harry sucks
|
The above schema is for storing comments made by people for books. Consider below queries:
- Comments by a person (join b/w comments and book table)
- Comments by a person on a certain book (join b/w person and comments table with a where clause on book table)
- Comments on a book (join b/w comments and book table)
For an application to answer such queries, application developer has to explicitly know about the schema to write SQL queries with joins at design time. Lets consider that in future the schema is enhanced to store author information as:
Author:
|
Id
|
Name
|
Book_id
|
|
1
|
Ram
|
Ramayan
|
With this additional data queries such as ‘Comments by authors’ can be answered, but this demands application code enhancement while if the above schema were implemented with graph database application code modification would be obviated.
In a nutshell if an application’s database schema has lot of tables to store relations between data, graph database is suited more than relational database, for such an application.
Triple Store
Triple store comes from the semantic web movement whose aim is large-scale knowledge inference. Here the smallest unit of knowledge is represented as a data structure in the form (subject, predicate, object), ‘subject’ representing the start node, ‘predicate’ representing the link while ‘object’ being the end node. Unlike property graph, nodes and links do not have any properties. This type of modeling is more suited for representing knowledge such that machines can automatically process it. They have inferencing capabilities for e.g. if A is parent of B and C is spouse of A then queries such as ‘parent of B’ will return both A & B. It is edge centric and scales horizontally with ease.
Figure 2: sample rdf graph
When to use?
Can be used for building semantic applications where application uses not only it’s domain data but data outside it’s domain. For e.g. an online booking system that shows interesting and live facts such as places to visit, recent and upcoming events about a place when an user books a ticket to that place.
Hyper Graph
It is a generalized graph model in which a relationship can connect any number of nodes. This is useful in the cases where domain objects have primarily many to many relationships.

Not many graph technologies use hyper graph except few in Artificial Intelligence and visualizing technologies.
References
[1] The Graph Traversal Pattern – Marko A. Rodriguez, Peter Neubauer
[2] Neo4j in action – Jonas Partner, Aleska Vukotic, Nicki Watt.








