


What is Kafka
Apache Kafka is an open-source and distributed streaming platform used to publish and subscribe to streams of records. Its fast, scalable, fault-tolerant, durable, pub-sub messaging system. Kafka is reliable, has high throughput and good replication management.
Kafka works with Flume, Spark Streaming, Storm, HBase, Flink for real-time data ingestion, analysis, and processing of streaming data. Kafka data can be unloaded to data lakes like S3, Hadoop HDFS. Kafka Brokers works with low latency tools like spark, storm, Flink to do real-time data analysis.
Topics and Partitions
All the data to Kafka is written into different topics. A topic refers to the name of a category/feed name used for which storing and publishing records. Producers write data to Kafka topics, and consumers read data/messages from Kafka topics. There are multiple topics created in Kafka as per requirements.
Each topic is divided into multiple partitions. This means messages of a single topic would be in various partitions. Each of the partitions could have replicas which are the same copy.
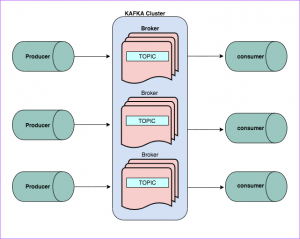
Consumers
It’s the process which reads from Kafka. It can be a simple java program, python program, Go code or any distributed processing framework like Spark Stream, Storm, Flink or similar.
There are two types of Kafka consumers-
Low-level Consumer
In the case of low-level consumers, partitions and topics are specified as the offset from which to read, either fixed position, at the beginning or the end. This can, of course, be cumbersome to keep track of which offsets are consumed, so the same records aren’t read more than once.
High-Level Consumer
The high-level consumer (more commonly known as consumer groups) comprises more than one consumer. In this case, a consumer group is built by the addition of the property “group.id” to a consumer. Giving the same group id to any new consumer will allow him/her to join in the same group.
Consumer Group
A consumer group is a mechanism of grouping multiple consumers where consumers within the same group share the same group id. Data is then equally divided among consumers falling into a group, with no two consumers, from the same group, receiving the same data.
When you write Kafka consumer you add a property like below
props.setProperty(“bootstrap.servers”, “localhost:9092”);
props.setProperty(“group.id”, “test”);
So consumers with the same group id are part of the same consumer group. They will share the data from the Kafka topic. Consumers will read only from those partitions of Kafka topic, where Kafka cluster itself assigns them.
Partitions and Consumer Group
What happens when we start consumer with some consumer group. First, Kafka checks if already a consumer is running with the same consumer group id.
If it is a new consumer group ID, it will assign all the partitions of that topic to this new consumer. If there is more than one consumer with the same group ID, Kafka will divide partitions among available consumers.
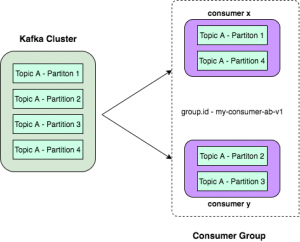
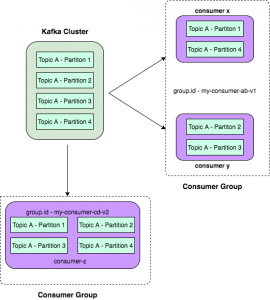
If we write a new consumer group with a new group ID, Kafka sends data to that consumer as well. The data is not shared here. Two consumers with different group id will get the same data. This is usually done when you have multiple business logic to run on data in the Kafka.
In the below example consumer z is a new consumer with different group id. Here, only a single instance of a consumer is running, so all four partitions will be assigned to that consumer.
When to use the same consumer group?
When you want to increase parallel processing for your consumer application, then all individual consumers should be part of the same group. Consumers ought to be a part of a similar group when the consumer carrying out operation has to be scaled up to process in parallel. Consumers, who are part of a common group, would be assigned with partitions that are different, thereby leading to parallel processing. This is used to achieve parallel processing in consumers.
When you write a storm/spark application, the application uses a consumer id. When you increase the workers for your application, it adds more consumers for your application and increases parallel processing. But you can add consumers the same as that of a number of partitions and can’t have more consumers than the number of partitions in the same consumer group. Basically, partitions are assigned to one consumer.
When to use different consumer groups?
When you want to run different application/business logic, consumers should not be part of the same consumer group. Some consumers update the database, while another set of consumers might carry out some aggregations and computations with consumed data. In this case, we should register these consumers with different group-id. They will work independently and Kafka will manage data sharing for them.
Offset management
Each message in the partition would have a unique index that is specific to the partition. This unique id is called offset. It is usually a number that indicates the count of messages read by a consumer, and it is usually maintained according to consumer group-id and partition. Consumers belonging to different groups can resume or can pause independently of the other groups, hence creating no dependency among consumers from different groups.
auto.offset.reset
This property takes control over the behavior of a consumer whenever it starts reading a partition it doesn’t have a committed offset for/ if the committed offset is invalid as it aged out because of an inactive customer). The default says latest- that indicates ‘on restart’ or new application will start reading for newest Kafka records The alternative is “earliest”, which means on restart or new application will read all data from start/beginning of Kafka partitions.
enable.auto.commit
This parameter is used to decide whether the consumer should commit offsets automatically or not. The default value is set to true, which means Kafka will commit offset on his own. If the value is false, the developer decides when to commit offset back to Kafka. This is highly essential to minimize duplicates and avoid missing data. In case you set enable.auto.commit as true, then it’s also necessary to minimize duplicates and avoid missing data. If you set to true, then you might also want to control how frequently offsets will be committed using auto.commit.interval.ms.
Automatic Commit
The easiest and best way to commit offsets is by allowing your consumer to do it for you. If you set value for enable.auto.commit as true, then Kafka consumer will commit the largest value of offset generated by poll() function every five seconds.
The interval of five seconds is by default and is taken control by setting auto.commit.interval.ms.
But if your consumer restarts before 5 seconds then there are chances that you process some records again. Automatic commits are easy to implement, but they don’t give developers enough flexibility to avoid duplicate messages.
Manual Commit
Developers want to control when they wish to commit offset back to Kafka. As normally applications read some data from Kafka, some processing and save data in the database, files, etc. So they want to commit back to Kafka only when their processing is successful.
When you set enable.auto.commit=false, the application explicitly chooses to commit offset to Kafka. The most reliable and simple of all the commit APIs is termed as commitSync(). This API commits the offset returned lately by poll() and again return as soon as the offset is committed, throwing back an exception in case of a commit failure.
One drawback of the manual commit is- application is blocked until the broker reverts to the commit request. This, in turn, limits the application’s throughput. To avoid this, asynchronous commit API comes to the picture. Instead of waiting for the response to a commit from the broker’s side, we can send out the request and continue on. The drawback is that commitSync() will continue re-trying the commit till the time it succeeds or encounters a non-retriable failure, commitAsync() will not retry. Sometimes, commitSync() and commitAsync() together are used to avoid re-try problems if the commit is failed.
You May Also Interested In: Kafka Benchmarking
Conclusion
We have checked here what a consumer is, how the consumer group works, and how we can parallelize consumers by using the same consumer group id. We have also checked on to do offset management when working with an application.









