


Recently, I got a chance to work on the scaling of a project scheduling application. Typical projects have somewhere around 100 to 1000 activities. These activities have predecessor and successor relationships between them, collectively forming a project network. Further, the activities have their durations, resources, and work calendars. We wanted to scale this to a level where a user can schedule a very large project network (such as the repair of an Aircraft Carrier) with 100K+ tasks, all the while staying within defined time and space boundary and transferring heavy data to the server.
Improving the performance of such a complex application can be a daunting task at first because the very heart of the application needs revamps. If the project does not have unit testing in place, it may even look like a non-starter. To accomplish such an endeavor, one needs to adopt a foolproof strategy aligned well with successful outcomes. Even though we ended up changing a lot of data structures along with placing a new scheduling algorithm, here in this article we will not focus on algorithmic solutions but on new design plans that can drive meaningful incremental changes with testability in mind. The following strategy can be applied to small performance tunings as well and can go a long way in meaningful results.
Naive Approach
One might get tempted to take a naive approach to optimize the time and space of all the code equally. But, be prepared for the fact that 80 percent of the optimization is destined to be wasted as there is a high chance that you may optimize code that hasn’t got enough time to run. All the time involved in making the program fast and getting back the lost clarity will surely be wasted. Hence, we bring you a suggested approach that is distilled out of our experience in enabling successful performance tunings.
Suggested Approach
Define time and space constraints
The time and space constraints are driven by user experience, application types (web app vs desktop app), application need, and hardware configuration. There should be enough clarity on the API request payload and target response time before you start on a new assignment.
Identifying the Hotspots
The interesting thing about performance is that if you analyze most programs, you’ll find that they waste most of their time in a small fraction of the code. You begin by running the program under a profiler that monitors the program and tells you where it is consuming time and space. This way, you can find that part of the program where the performance hotspots lie. There can be more than one hotspot and hence two approaches, fix the low-hanging ones up front and then move to the more complex ones or vice-a-versa.
Refactor before fixing
Fixing these hotspots without refactoring is not a good strategy. While encapsulating the hotspot, a developer gains more understanding of the underlying code too. If it is simple, a function may be sufficient for the job; however the need to maintain some invariant properties uncompromised calls for a class encapsulation. A very useful design pattern here is a strategy pattern when you can have different variants of an algorithm reflecting different space/time trade-offs.
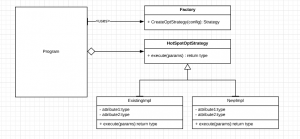
Strategy along with factory pattern provides great flexibility. If you have observed, the factory takes config params such that we can control the instantiation of the desired implementation at run time. Refactoring is important because the switching between implementations will help you in testing the new implementation. Note that we have already mentioned that there can be many hotspots and hence the above pattern may need to be implemented/repeated in many places in the program, each with specialized intention/purpose i.e. encapsulating the hotspot.
Functional Verification and Plugging the Alternative Optimized Implementation
Once the refactoring is done, the next step is to write unit test cases against the refactored code to ensure that the program is still functionally correct. You are now ready to implement/ plug your new optimized algorithm. The good part is that while refactoring and writing unit test cases, the developer gains enough understanding of the code as well as different considerations/cases that need to be taken into account for the new optimized algorithm. Please note here that those same unit test cases that are written for functional verification need to pass against the new optimized implementation as well.
Even if you write many unit test cases, you may miss some scenarios and data related edge cases. To overcome that and to establish the correctness of the new implementation, there is a powerful technique called stress testing. In general, stress testing is nothing but a program that generates random tests (with random inputs) in an infinite loop, it executes the existing algorithm and then the new algorithm on the same test/inputs and compares the results. After this, you wait for a test case where the solution differs. The assumption here is that your existing algorithm is correct even though it is not time-optimized and space-optimized. All these can be done if abstractions and class interfaces are well-designed and refactored well for the said hotspot.
Nonetheless, unit testing cannot entirely replace the whole system integration along with manual testing. But, while doing changes in the critical area, unit testing must be implemented at least for the changes that are already done (refactoring + new implementation).
Given below is the strategy blueprint for your reference:
PROCEDURE :
PERFORMANCE-TUNING-STRATEGY(desired time and space constraint)
while( time and space constraint > desired)
run profiler
pick the top hotspot
refactor the hotspot(using strategy + factory pattern)
write unit test for refactored code/Existing Impl/algo
implement the new Impl/algo
passed = run same unit test cases against the new impl/algo
if(passed)
STRESS-TEST()
run whole system integration test
Deploy in production
END
PROCEDURE:
STRESS-TEST()
while(unsatisfied)
generate random input
call existing impl/algo
call new impl/algo
isEqual = compare new vs existing
if(!isEqual)
dump the difference
break( fix the issue + repeat STRESS-TEST)
END
The above procedure takes the assumption that the developer does not have much knowledge about the code, hence refactoring + unit test upfront. Even if someone has a good understanding of the code and may get tempted to implement the solution directly, it should be avoided. Be mindful of the fact that the new developers are going to work on the same code in the future when the original developer is not around. These refactoring and unit test cases will help the product immensely in the later stages all the while enabling the team to incorporate future changes easily.
Deploying the Solution
In cloud setup with server-side applications you may want to perform a rolling upgrade, deploy the new version to a few nodes at a time, check whether the new version is running smoothly, and gradually work your way through all the nodes. In a private cloud setup where access is limited, the switching between the new and existing through the configuration can be very handy (if anything goes wrong) till you get access to the server.
Conclusion
While doing any algorithmic changes, less focus on the cleanliness of code and structure of design can result in system complications that may occur in the future. Moreover, a complex system is inherently difficult to justify in terms of accuracy at the system level when multiple components are at play. Even we use mathematical proof to justify the correctness of algorithms, but it is a laborious process of formally proving every function. Hence, the only meaningful way is the scientific way to prove and establish things.
Scientific theories cannot be proven correct but can be demonstrated with experiments (unit test cases at function level). Likewise, software needs to be tested to prove its correctness, and a well thought out plan is required to be in place. If your project does not have unit testing in place, don’t get tempted to write unit test cases equally for all the codes but follow the Eisenhower Matrix. Unit testing of your refactored code (mentioned above) belongs to quadrant 1 (a point to be taken not of). Dijkstra once said, “Testing shows the presence, not the absence of bugs”. So, for some mental peace, you can give stress testing a stab and see what wonder it does with performance tuning.








