


Before we dive into breaking and testing large classes, we need to understand what a large class actually is. A common method to avoid any unnecessary problem is “Prevention is better than cure.” So, we will first discuss how to avoid it.
I will then discuss why it is difficult to avoid large classes in a fast-paced development environment, especially at the initial development phase. We will then focus on fixing and refactoring it.
If you ask me, I will say “Friendly Builder” is the right pattern to tackle large classes. I have the experience of handling it in one of our projects at Talentica. Since we have implemented it in a C++ project, I will discuss it in C++ here. However, this is one program that you can also use with C# and Java as well using inner class constructs.
What is a large class?
A large class is the one that has more than one responsibility. Most of the time, we tweak existing features a bit while developing the product and developers add the new code in the existing classes.
Gradually after some time, the classes become bulky. This happens in sync with the law of Least Effort. In simpler words, when it comes to deciding between similar options, people naturally gravitate towards the option that hardly requires any effort. After all, they just need some addition of little code and maybe a few more methods that appear very harmless then.
All these do not happen overnight. It is a slow process and equally difficult to manage as the definition of the large class is as nebulous as the Single Responsibility Principle.
What is the problem with so-called large classes?
Well, when a class has many methods (hence many responsibilities) and member variables, the understanding of the effects of changing a particular method or variable becomes complicated. Sometimes, these unsettle a developer, especially when the required changes are more invasive and demand a proper understanding. On top of it, these bulky classes are inherently difficult to test.
How to avoid leading to a large class?
As we said “Prevention is better than cure”, There are two methods mainly described by Michael C. Feathers in his book Working Effectively with Legacy Code, and they are :
Sprout Method: If you have added a feature to a system, which can be entirely formulated as new code, take the pain to write the code anew. Call it from the places where the new functionality needs to be. Assuming that you can create objects of that class in a test harness easily, you can write tests for the new code. This technique works as long as the new code is not an added responsibility to the existing class.
Sprout Class: Consider a case in which you have to make changes to a class, but there is no way to create objects of that bulky class in a test harness in a reasonable amount of time. It means there is no way to sprout a method and write tests for it on that class. Maybe you have a large set of creational dependencies, things that make it hard to instantiate your class, or you have many hidden dependencies.
To get rid of them, you need to do many invasive refactorings to separate them well enough to compile the class in a test harness. In these cases, you can create another class to hold your changes and use it from the source class. Moreover, if the added code is a piled-on responsibility, it is always better to delegate it to a new class. The good side is that we can test the newly added code since it resides in a separate class.
Are these two methods sufficient?
When the product is in the MVP stage or very early phase, very few developers work on the product idea. Deadlines also remain very tight. In this phase, the goals are different. The aim is to quickly enter the market, get early feedback, understand the need, and make improvements rapidly to make it market fit.
Moreover, the so-called Large classes are bad when new or more than one developers work on them. This happens typically at the growth phase because companies start hiring more people then. During this development phase, the focus shifts to maintaining a speedy development without breaking the existing functionalities. We need to set the quality standard very high at this stage to ensure the customer doesn’t have a negative experience.
People love to argue about doing MVPs with TDD vs. without TDD, but we will suspend judgment for now. We will explore systematic ways to handle it if we have to work with large classes. Believe me, most often, we do end up with large classes in our code.
How to break a Large Class?
Let’s discuss what tools are available to break a large class. Among all, which I find very useful is the “Feature sketches” method (Again coming from Michael C. Feathers’s book). It is a great tool for finding different responsibilities in the class. Let’s take an example.
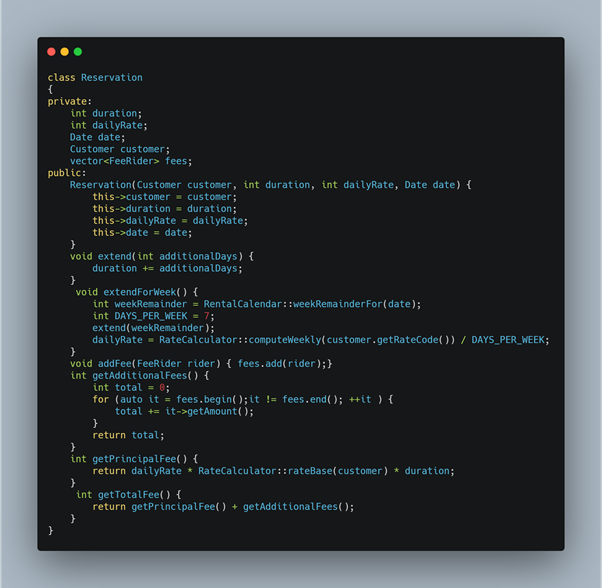
The first step is to draw circles for each method and member variable and then draw lines from each method to the instance variables and methods it accesses or modifies. For the example taken, we will have the following feature sketch.
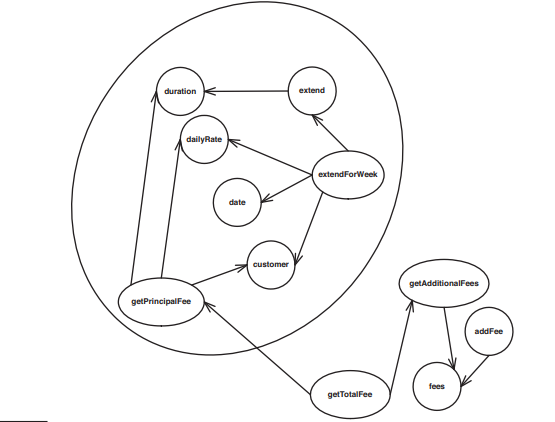
As you see, a few clusters are forming. Take two clusters at least. These two clusters can help us find different responsibilities. But in addition to helping us find responsibilities, feature sketches allow us to see the dependency structure inside classes, and that can often be just as important as responsibility when we are deciding what and how to extract/refactor.
The Dilemma
All these are good, but the bigger question is should we break the class into little bits? If you have time (especially at the start of the sprint), then do it. Most often, it is not the case. Moreover, after any large refactoring exercise, the state of the product will be broken for a few days even if developers do the refactoring very carefully.
What is the way forward once you identify the responsibility and you are short of time to refactor or don’t want to take the risk of large refactoring, at least for the time being?
It would be good if we can test these identified responsibilities without refactoring and at the same time, you do your required changes. This way, you have tested your code and make things easier when you decide to refactor later, which is inevitable.
Testing responsibilities using Friendly Builder Pattern
The goal is to make very few changes in the large class but still be able to test the identified responsibilities. A common issue while testing large classes is that they are difficult to create/ instantiate in the test harness because of multiple creational dependencies. As it is large, it is bound to have many dependencies. Consider the following code.
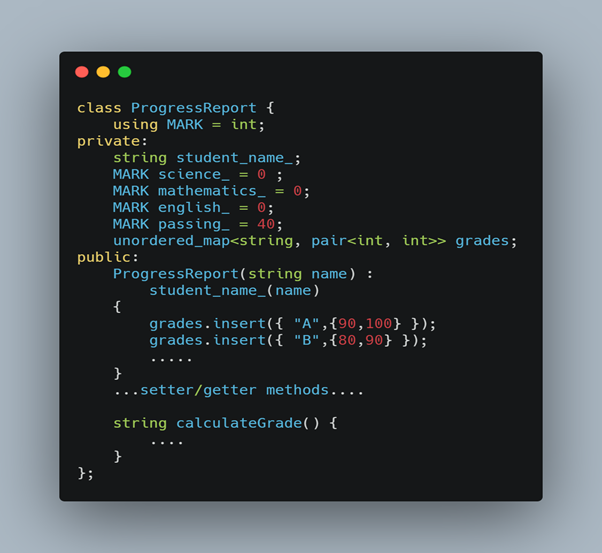
Here is the ProgressReport class.
Below is the classroom class.
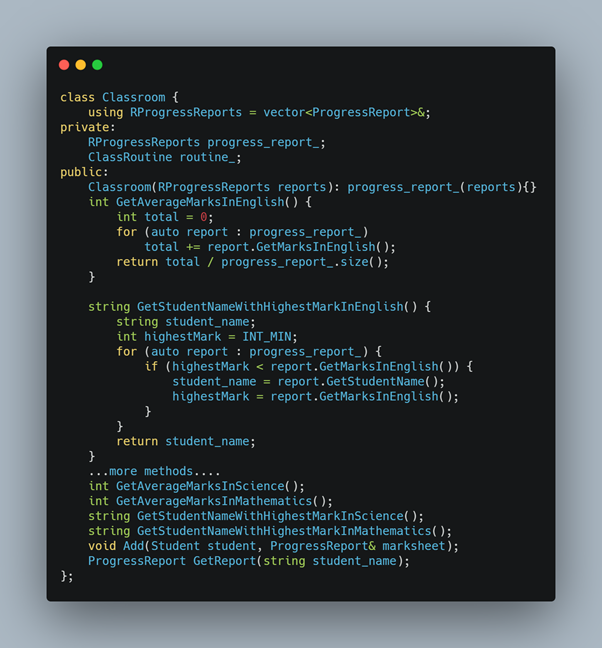
If you want to test the “GetAverageMarksInEnglish” method, you don’t need the complete “ProgressReport” object. You need only English marks in it. Similarly, for the method “GetStudentNameWithHighestMarkInEnglish” to test, we need the English number and the student name. You require the full “ProgressReport” object if you want to calculate the Grade. So this means that we may not need to populate the whole object to test a particular function.
Also, the “Classroom” class holds both the daily class routine and the Progress Report of all students. To test “GetAverageMarksInEnglish”, we don’t need the daily class routine object. It can be a null or empty object. So, suppose somehow we get access to the private method and variables of a class. In that case, we can actually populate/fill the object partially as per the testing requirement of identified responsibilities.
“A friend in need is a friend indeed”
In C++, the friend concept is indeed your real friend here. It provides full access to class internals. You must have heard about the builder pattern too; it is a creational design pattern for the step-by-step construction of complex objects (large class). The pattern helps you produce different types and representations of an object where you can use the same construction code. The different representations here refer to the need for the large class’s partially populated object to test different or the targeted responsibility.
In a nutshell, here is what you need.
- Every class should have an empty constructor (if not, then constructor with minimal parameters for aggregation/dependency injection pattern)
- Define the builder class as its friend to get access to the class internals.
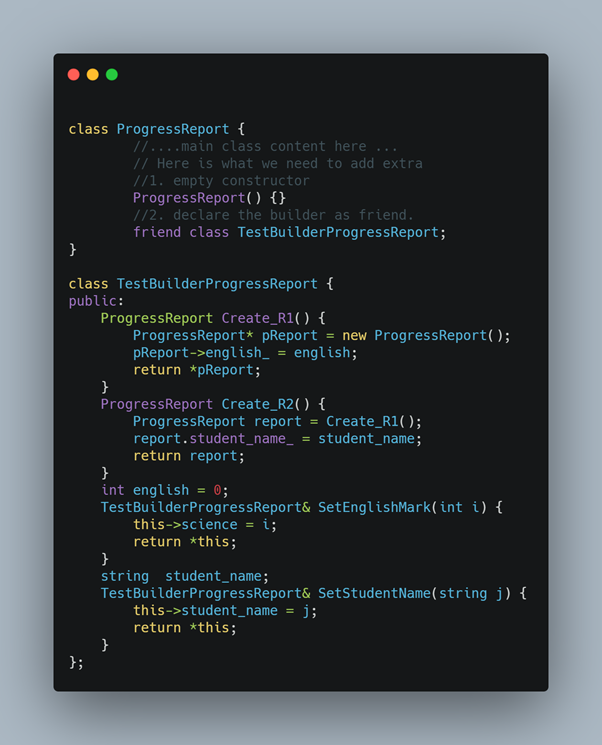
You can create different representation (i.e. Create_R1,Create_R2 etc) to test potentially different responsibilities i.e. GetAverageMarksInEnglish and GetStudentNameWithHighestMarkInEnglish. You must have already figured out that you can have a class that just calculates average marks given some marks as input. That means calculating the average can go to a different class. Till you don’t refactor your code, you can have multiple create methods for each responsibility in the builder class and test them.
You may argue, the ProgressReport class is too simple. What if the large class has an aggregation relation with some other classes? Aggregation uses references (in C++) as the member object is not owned by the referring class, and also, their lifetimes are not bound, unlike a composition. You won’t be able to create an empty constructor. Likewise, “Classroom” cannot create an empty parameter constructor as ProgressReport can exist independently. In this case, we need to create a constructor having a minimum number of parameters, i.e., at least with “ProgressReport”. If you implement a similar pattern for these referenced member object classes (i.e., for ProgressReport, which we did), it is not that difficult to bring them into the test harness.
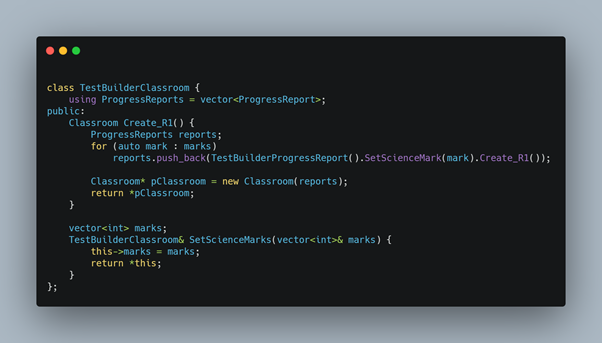
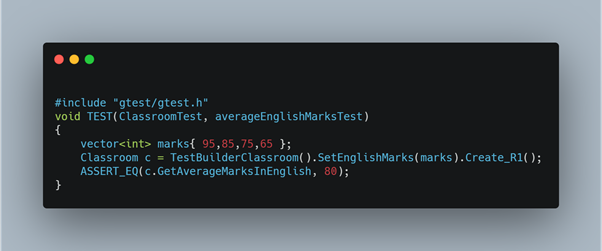
Test code:
The above approach should work for composition and aggregation. Still, if the large class uses inheritance and you need access to some base class’s private variable, you may have to define them from private to protected. The friend class cannot access the private member of the base class.
The real limitation is when your class has a dependency on a third-party library object as you can’t go and modify that class. Here, you have to extract the dependency and move to an interface to inject/ initialize a fake test object in your builder class.
What Next?
Suppose we never refactor our code and keep implementing this pattern again and again as we do new development. In that case, we introduce the overhead of maintaining the builder class as it will eventually become bulky over time. The Next thing is to break the large class for the identified responsibilities, which you can refactor as you have the unit test cases at your disposal. Since this refactoring is not much risky, you can do it whenever you have time.
Conclusion
As you make changes to your large class, you should always try to apply the Sprout Method and Sprout Class for the new changes to avoid making the class bulky. But suppose the class is already bulky and caters to a lot of responsibilities. In that case, you may need to draw the feature sketch diagram to figure out the responsibilities and their dependencies. If you want to avoid the risks of refactoring the code, you can apply the friendly builder pattern to test your impacted code. Refactoring can be a choice, but unit testing cannot be, especially if the goal is to have good quality with speedy development.
Over time, the different clusters/responsibilities of the large class will be covered in your test cases. Later, when the team has time to work on technical debt (especially at the start of the sprint), they can easily refactor some of these classes. They can just concentrate on the client code, which uses this large class.
The friend construct is not available in other languages except C++. But inner classes (in Java, C#) do allow accessing the private variables of the outer class. You need to write your builder class as an inner class in C# and Java.








