

Accidents like deleting an entire cluster in blockchain by mistake happen. And when they do, they trigger catastrophic events. If you have faced a similar scenario, then you probably know the smartest way to avoid such incidents is to have a proper data backup. Having data in reserve is crucial when you are working with a Hyperledger Fabric on Kubernetes for the same reason. Together, they offer a powerful and highly secure platform to process blockchain transactions. The fabric is an open-source blockchain framework hosted by The Linux Foundation, and it provides a platform for all distributed ledger-related solutions.
Hyperledger Fabric has advantages like high performance and scalability. It provides a high level of trust to participants with known identities and support for rich queries over an immutable ledger.
In this blog, I will share a step-by-step guide of how you can back up and restore data on Hyperledger Fabric running on Kubernetes without any complications. But first, let us start with a proper understanding why you need a backup of your data.
Need for backup
As I have mentioned already in the introduction, having a backup is a must. Here are the reasons –
1. Reliability
Having data backup can let your team enjoy a bit of freedom. If you are using Cloud to back up the data, then you are adding an extra layer of security to prevent different types of data loss caused by events like natural disasters, human errors, or ransomware.
For example, if an error like pod restarting or crashing occurs while configuring the right mount path for an app in the deployment specification, then you will lose the data.
2. Resilience
Data backups can make your applications more resilient to unexpected crashes and errors. For example, you might lose data if a team member accidentally deletes one of the volumes.
Having a backup will enable you to restore the apps with the latest state.
3. Security and Compliance
It also makes your entire application more secure and compliant to standards by protecting your application from unexpected data corruption and attacks.
4. Changes to Infrastructure
Data backup helps in navigating through infrastructure changes. For example, if you are migrating your Fabric network to a different cloud provider, then, you might have to use a different type of storage mechanism to lower the cost.
Deployment
In this blog, I have assumed that you have setup a Hyperledger Fabric network on Kubernetes with a dedicated namespace for every organisation wherein all its services run before.
If not, please refer to our blog on things to consider before deploying Hyperledger Fabric explaining extensively how you can do it. You may have to customize it to suit your requirements.
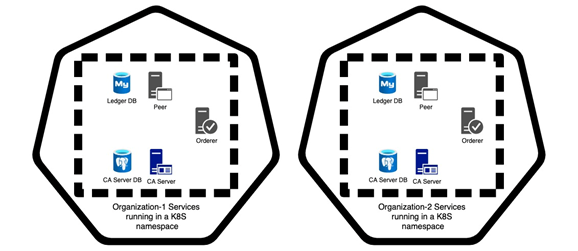
Now, your Fabric network setup should have a namespace for every organisation and every namespace will have the following types of deployments:
- Peer
- LedgerDB
- CA server (if this organisation needs to register new identities)
- CA server DB
- Orderer (if this organisation contributes an orderer)
How does a Kubernetes application stores data?
To function, a stateful application has to store and retrieve data. The application can take up this responsibility or delegate it entirely or partially to another stateful application (DBs). Ultimately, all these data persist in the form of file(s) or folder(s).
Moreover, they are usually configured to use specific file paths where they persist data. K8S deployments achieve data persistence through a combination of PVC mounts backed by a PV, configmaps and secrets. Some sensitive data like the cryptographic keys and certificates are mounted as secrets. Some configuration data like the yaml files are mounted as configmaps. The files and folders that are present in all the PVC mount paths, secrets, and configmaps make up the data for that deployment.
Peer
In the case of Peer, some of the data is stored and managed locally (at /var/hyperledger, by default) and the rest is delegated to a LedgerDB.

- tls/server folder contains the tls certificate and key pair of the Peer.
- fabric-cfg folder contains core.yaml file that contains the configuration with which the Peer was started.
- msp folder contains the Peer msp, its enrolment certificate and key, certificate chain of the CA server.
- admin-msp folder contains admin msp.
- Production folder contains some of the ledger data, like the blockchain, chaincode that are installed and their lifecycle information, private data stores and transient store (the one included while submitting the transaction).

Orderer
In the case of Orderer, most of the data is stored and managed locally (again at /var/hyperledger, by default).

- Some of the folders are same as the ones in Peer, except that these contain the Orderer MSP, its tls cert-key and enrolment cert-key.
- Ledger folder contains the chains that this ordering service is part of and pending operations.
- Production folder contains the etcdraft consensus specific files and snapshots.

CA Server
In the case of CA server, some of the data is stored locally (again at /var/hyperledger, by default) and the rest is stored in the CA Server DB.
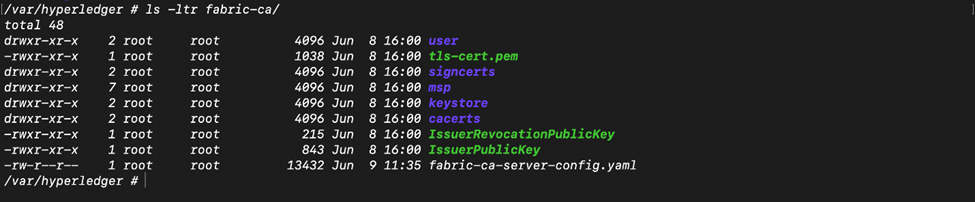
- fabric-ca folder contains the CA server certs, tls certs, config files this service was started with.
- You might want to retain and use the new tls certs(tls-cert.pem and it’s corresponding private key in the keystore folder) and the fabric-ca-server-config.yaml for the CA server because it reflects the latest tls profile changes, while replacing the rest of the contents like enrolment certs (signcerts, cacerts, keystore, etc.) with the contents in the old cluster.
Backup Strategy
First of all, make sure to backup the secrets and configmaps. There are many ways of backing up data residing in volumes. One way is to take snapshots of the volumes these services use, refer to this link. Another way is to use a service or a tool specifically built for this purpose like Velero, Stash.
Choose the right backup strategy as per your needs and context as some of these approaches might make it easier to migrate your workload across clusters whereas some might not.
Restore Mechanism
Restore strategy depends on the backup strategy. You have to refer to the appropriate restoration guide. First, recreate the secrets and configmaps from the backed up data. Next, put the services to sleep and copy the backed up data to the pod. Repeat this for all the services across all the namespaces. It takes care of restoring the normally mounted data. Now, start the independent services like ledgerDB and CA server DB first and then the rest.
Testing Back-Up Consistency
Hyperledger Fabric, being a distributed system, introduces data consistency challenges in backup and restore process. At a given point of time, the blockchain height across peers may be different due to various reasons like network speed, geographical proximity, or the type of the peer.
The leader peers are the first to receive a block from the ordering service, so, they may be the ones to commit it first. Some peers might have had internal crashes that they recovered from by retrying the steps and so, naturally they might have committed the block late.
We can mitigate this in two ways, first of all, have a no transaction window in which no transactions are sent to the network. Next, query the blockchain ledger state using the peer CLI commands to make sure that all the peers are at the same height before you start the backup process. After restoring the data, you could repeat the above process to make sure that the restore is done properly. You must check the peer and orderer logs to make sure everything is working fine.
Conclusion
In this blog, I have discussed how and where a Fabric network on Kubernetes stores data, advantages of backing up data, and how to restore or migrate a network along with some tests to ensure the same.
If you come across any difficulty in carrying out the process do reach out to us in the comments section. Also, do not forget to share your experience of carrying out the entire backup process with us.








