


(A Quick Note for the Readers- This is purely an opinion-based article distilled out of my experiences)
I’ve been a part of many architecture-based discussions, reviews, and implementations, and have shipped many systems based on microservices to production. I pretty much agree with the ‘Monolith first’ approach of Martin Fowler. However, I’ve seen many people go in the opposite direction and justifying the pre-mature optimization. This can lead to an unstable and chaotic system.
It’s highly important to understand if you are building microservices just for the purpose of distributed transactions, you’re going to land onto great trouble.
What is a Distributed System?
Let’s go by an example, in an e-commerce app this will be the order flow in a monolithic version
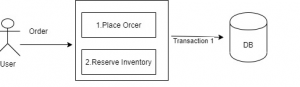
In Microservice version, the same thing will be like this
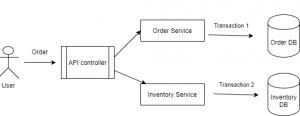
In this version, the transaction has two parts based on services. The atomicity needs to be managed by the API controller.
You need to avoid distributed transactions while building microservices. If you’re spawning your transactions in multiple microservices or calling multiple rest APIs or PUB/SUB, which can be easily done with an in-process single service and a single database, then there’s a high chance that you’re doing it the wrong way.
Challenges in Using Microservices to Implement Distributed Transactions
- Chaotic testing: As compared to the ones in in-process transactions, it’s really hard to stabilize features written in a distributed fashion. This is because you not only test happy cases but also cases like service down, timeout, and error handlings of rest APIs.
- Unstable and intermittent bugs: You will start seeing these during production.
- Sequencing: In the real world, everyone needs some kind of sequencing when it comes to transactions. But it’s not easy to stabilize a system that is asynchronous (like node.js) and distributed.
- Performance: It is crucial and is a by-product of premature optimization. Initially, your transactions might not handle big jsons, but might appear later, and in-process where the same memory is accessible to subsequent codes and transactions. In the microservices world, where a transaction is distributed, it could be painful. It is because every microservices load data, serialize and deserialize, or same large DB calls multiple times.
- Refactoring: Every time you make changes in the design level, you will end up having new problems (1-3). It leads to the engineering team a mod “resistant to change”.
- Slow features: The whole concept behind microservices is to “build and deploy features independently and fast”. But now you may need to build, test, stabilize, and deploy a bunch of services and it will slow down.
- Unoptimized hardware utilization: There is a high chance that most of the hardware will be underutilized and you might start shipping many services in the same container or same VMs. This will result in high I/O. Suddenly, if some big request comes into the system, the system may turn hyper utilized. Subsequently, you will have to separate that component. However, it will make the system under-utilized if these kinds of requests are not coming anymore. This will trigger an infinite oscillation that could have been easily avoided.
Do’s & Dont’s for Building Microservices from Scratch
- Microservices is not like refactoration of code in varied directories. If some code files seem to be logically separated, it’s always a good idea to separate them in one package. However, to create a microservice herein is nothing but premature optimization.
- If you need to call rest APIs to complete a request, think twice about it (I would rather recommend to avoid it completely). Same goes for a messaging-based system before creating new producers and consumers, try not to have them at all.
- Always focus on different user experiences and their diverse scaling requirements. For instance, e-commerce vendors’ APIs are bulky and transactional, as compared to consumer API, it’s a good way of identifying components.
- Avoid integration tests (yes, you just heard it right ). If you create 10 services and write hundreds of integration tests, you’re creating a chaotic situation altogether. Instead, start with 2-4 services, write hundreds of unit tests, and write 5 integration tests, which you won’t regret later.
- Consider batch processing, as this design would turn out to be good in performance and less chaotic. For instance, let’s say in e-commerce, you have products in both vendor and consumer databases. Herein, instead of writing distributed transactions to make new products in both the DBs, you can first write only in the vendor DB and run batch processes to pick 100 new products and insert them into consumer DB.
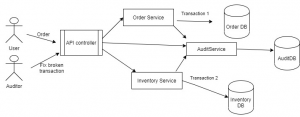
- Consider setup auditor or create your own. You’ll be able to debug and fix an atomic operation when it fails instead of looking into different databases. In case you wish to reduce your late-night intermittent bug fixes, set this early on and use it in all places. So, the solution could be like this

- I would recommend to overlook synchronization. I have seen many people trying to use this as a way to stabilize the ecosystem, but it introduces new problems (like time-outs) than fixing them. In the end, services should remain scalable.
- Don’t create partitions for your database early. If possible let every microservice have its own database but not all of them need it. You should create persistent microservices first, and then try to use them inside other microservices. If most/all microservices are connecting to Databases then it’s a design smell, scale the persistent microservices horizontally with more instances.
- Don’t create a new git repository for new microservices, first create well unit-tested core components, reuse (don’t copy) them in high-level components, and from a single repository, you might be able to spawn many microservices. Every time you need same code in another repository don’t copy them, rather move it to the core component. Write a super quick unit test, and reuse it in all microservices.
- Async programming can be a real problem if you write transactions in proper sequence handling. There might be some fire and forget scenario. But in regress or heavy load, these fire and forget might not even exected lead to inconsistent scenarios.
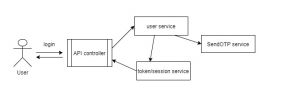
Check the above example here developer thought calling send OTP Service don’t need to synchronize and did classic “fire and forget”, now in normal testing and low load OTP will be sent always but in heavy load sometimes send OTP would not get chance to execute.
Microservices Out of Monolithic: A Cheatsheet
- 1-5 of the above-mentioned are applicable
- Forget big-bang, you have a stable production system (might not be scalable though) and have to still use 50-70% of the existing system in the new one.
- Start collecting data and figuring out pain points in the system, like tables, non-scalable APIs, performance bottlenecks, intermittent performance issues, and load testing results.
- Make a call over scaling by adding hardware vs optimization. However, there’s a cost involved in both cases and you’ll have to decide which is lower. Many a time it’s easier to add more nodes and solve a problem. But optimizing the system might involve development and testing cost, which might be way higher than just adding nodes.
- Consider using the incremental approach. For example, let’s say I have an e-commerce app that is monolith (vendor and consumer both), and I come to know that we will scale with new vendors in the coming six months. The first intuition would be to re-architect. However, in the case of the incremental approach, you will realize that your biggest request hit will be from the consumer side and product search. You will have to refactor the product catalog. So you will not change anything in the existing app and it will work as it is for all vendors’ APIs and consumer transactions. Only for the new problems, you will have to create another microservice and another DB. You will also have to replicate the data using batch processing from primary DB. Then you need to redirect all search and product catalog APIs to the new microservice.
- Optimization, you’ll have to shift your key area of focus to optimizing problematic components. This is because scaling with adding more hardware might not work here.
- Create partitions for your DB to fix problems (don’t ignore this). Many people out there might not agree to this but you need to fix the core design problems instead of adding a counter mechanism like caching.
- Don’t rush into new techs and tools. You should be using them when you have enough expertise and readiness in your team. Always pick stable opensource small projects instead of the new, trendy library or framework promising too many things.
Still Distributed Transactions in Microservices? Here’s the Way Forward
- Compositions, if you think you should merge a couple of microservices or integrate transactions in one service, it’s never late to do this exercise.
- Build consistent and useful audits for transactions, and make sure you always capture audits even your service gets timed out. A simple example would be setting up elk stack, structured logs with transaction ids, entity ids and the ability to define policies that will enable you to trace your failed transactions and fix them by data operation teams (this is supercritical). You need to fix these. If it comes to the engineering team then your audit setup might fail.
- Redesign your process for chaos testing. Don’t test with hypothetical scenarios (like killing a service then see how other components behave). Instead, try to produce the situation or data or sequences which can kill or time out a service. Then map how resiliency/retry works for other services.
- For new requirements, always do estimates, impact analysis, and build an action plan based on testing time and not development time.
- Integrate a circuit breaker in your ecosystem, so that you’ll be able to check whether all services- the ones going to participate in these transactions- are alive and healthy. This way you can avoid half-cooked transactions big time even before starting the transactions.
- Adopt batch process, wherein you convert some of the critical transactions in batch and offline to make the system more stable and consistent. For example, for the e-commerce example mentioned above, you can use the following-
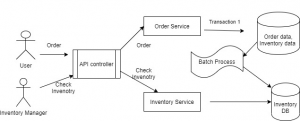
Here you will still get scaling, isolation, and independent deployment but the batch process will make it far more consistent.
- Don’t try to build a two-phase commit, instead go for an arbitrator pattern that essentially supports resiliency, retry, error handling, timeout handling, and rollback. This is applicable for PUB-SUB as well, with this you don’t need to make every service robust and just have to ensure that the arbitrator is capable of handling most of the scenarios.
- For performance, you can use IPC, memory sharing across processes, and TCP, if there are chatty microservices check for gRPC or WebSockets as an alternative to rest APIs.
- Configurations can become real nightmares if not handled properly. If your apps fail in production due to missing configuration and you are busy rolling back, fixing and redeploying, you would require something else here. It’s very hard to make every microservice configuration savvy. In fact, you will never figure out all missing configurations before shipping to productions. So, follow this
Hard code à config files à Databases à API à discovery
- Enable service discovery, in case if you haven’t.
Conclusion
You can use microservices instead of distributed transactions. But you must also have the pitfalls in the back of your mind. Avoid premature optimizations, and your target should be building stable and scalable products instead of building microservices. Monolith in distributed transactions is never bad, however, SOA is versatile and capable of measuring everything. You don’t require a system where everything is essentially microservices, rather a well-built system with the combination of monoliths, microservices, and SOAs that can fly really high.









