


HyperText Transfer Protocol (HTTP) is the most widely used application layer protocol in the Open Systems Interconnection (OSI) model. Traditionally, it was built to transfer text or media which had links to other similar resources, between a client that common users could interact with, and a server that provided the resources. Clicking on a link usually resulted in the un-mounting of the present page from the client and loading of an entirely another page. Gradually when the content across pages became repetitive with minute differences, engineers started looking for a solution to the only update some half of the content instead of loading the entire page.
This was when XMLHttpRequest or AJAX was born which supported the transfer of data in formats like XML or JSON, which differed from the traditional HTML pages. But all along the process, HTTP was always a stateless protocol where the onus lied on the client to initiate a request to the server for any data it required.
Real-time data
When exponential growth in the volume of data exchanged on the internet lead to application spanning multiple business use cases, the need arose to fetch this data on a real-time basis rather than waiting for the user to request a page refresh. This is the topic that we are trying to address here. Now there are different protocols and solutions available for syncing data between client and server to keep data updated between a third party server and our own server. We are limiting the scope only to real-time synchronization between a client application and a data server.
Without loss of generality, we are assuming that our server is on a cloud platform, with several instances of the server running behind a load balancer. Without going into the details on how this distributed system maintains a single source of new data, we are assuming that whenever a real-time data occurs, all servers are aware and access this new data from the same source. We will now disseminate four technologies that solve real-time data problems – namely Polling, Long Polling, Server-Sent Events, and WebSockets. We will also compare them in terms of ease of implementation on the client-side as well as the server-side.
Polling
Polling is a mechanism in which a client application, like a web browser, constantly asks the servers for new data. They are traditional HTTP requests that pull data from servers via XMLHttpRequest objects. The only difference is that we don’t rely on the user to perform any action for triggering this request. We periodically keep on pushing the requests to the server separated by a certain time window. As soon as any new data is available on the server, the immediate occurring request is responded with this data.
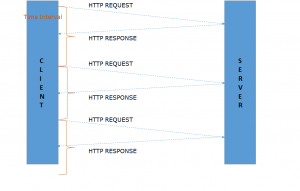
Figure 1: Polling
Ease of Implementation on client
- Easiest implementation
- Simply set up an interval timer that triggers the XMLHttpRequest
Ease of Implementation on Server
- Easiest to implement
- As soon as the request arrives, provide the new data if available
- Else send a response indicating null data
- Typically Server can close a connection after the response
- Since HTTP 1.1, as all connections are by default kept alive till a threshold time or certain number of requests, modern browsers behind the scenes multiplex request among parallel connections to a server
Critical Drawbacks
- Depending on the interval of requests, the data may not actually be real-time
- We must not remove the new data for the amount of time that is at least the same as an interval of requests, else we risk some clients being not provided with the data
- Results in heavy network load on the server
- When the interval time is reached, it does not care whether the request made earlier has been responded to or not; it simply makes another periodic request
- It may throttle other client requests as all of the connections that a browser is limited to for a domain may be consumed for polling
Long Polling
As the name suggests, long polling is mostly equivalent to the basic polling described above as it is a client pull of data and makes an HTTP request to the server using XMLHttpRequest object. But the only difference is that it now expects the server to keep the connection alive as long as it does not respond with new data or the connection timeout over TCP is reached. The client does not initiate a new request till the previous request is responded with.
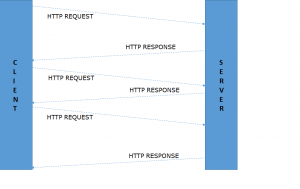
Figure 2: Long Polling
Ease of Implementation on client
- Still easy to implement
- The client simply has to provide a Keep-Alive header in the request with a parameter indicating the maximum connection timeout (Note that modern browsers implementing HTTP 1.1 by default provide this header i.e. by default the connection is kept alive)
- When the previous request is responded with, initiate a new request
Ease of Implementation on Server
- More difficult to implement than traditional request-response cycle
- The onus is on the server to keep the connection alive
- The server has to periodically check for new data while keeping the connection open which results in the consumption of memory and resources
- It is difficult to estimate how long should the new data be kept on the server because there can be cases where connections with some client had timed out in the moment when new data arrives and these clients cannot be provided with this data
Critical Drawbacks
- If data changes are frequent, this is virtually equivalent to polling because client will keep on making requests very frequently too
- If data changes are not that frequent, this results in lots of connection timeouts
- So a connection which could have been used for other requests is adhering only to a single request for a very long time
- Caching servers over the network between client and server can result in providing stale data if proper Cache-Control header is not provided
- As mentioned earlier, it is possible that some connections may not be provided with new data at all
Server-Sent Events
Server-Sent Events or SSE follows the principle of Server push of data rather than client polling for data. The communication still follows the standard HTTP protocol. A client initiates a request with the server. After the TCP handshake is done, the server informs the client that it will be providing streams of text data. Both the browser and server agree to keep the connection alive for as long as possible. The server in fact never closes the connection on its own. The client can close the connection if it no more needs new data. Now whenever any new data occurs on the server, it keeps on providing stream in text format as a new event for each new data. If the SSE connection is ever interrupted because of network issues, the browser immediately initiates a new SSE request.
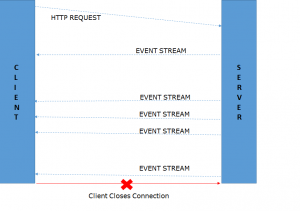
Figure 3: Server-Sent Events
Ease of Implementation on client
- The modern browser provides a JavaScript class called as EventSource which abstracts a lot of overhead functionality for client
- The client simply has to instantiate the EventSource class with the server endpoint
- It will now receive event call-back whenever a stream of text data is pushed by the server
- EventSource instance itself handles re-establishing an interrupted connection
Ease of Implementation on Server
- Over the traditional HTTP response headers, the server must provide Content-Type header as ‘text/event-stream’ and Connection header as ‘Keep-Alive’
- Each server has to remember the pool of connections with SSE properties
- The server has to periodically check for new data which results in the consumption of memory via an asynchronously running thread
- Since a consistent connection is almost guaranteed by all clients, the server can push new data to all connections from the pool and flush the now stale data immediately
Critical Drawbacks
- EventSource class is not supported by Internet Explorer
- The server must ensure to remove failed connections from the SSE pool to optimize resources
WebSockets
Unlike all the above three technologies which follow HTTP protocol, Websockets can be defined as something that’s built over HTTP. The client initiates a normal HTTP request with the server but includes a couple of special headers – Connection: Upgrade and Upgrade: WebSocket. These headers instruct the server to first establish a TCP connection with the client. But then, both the server and client agree to use this now active TCP connection for a protocol which is an upgrade over the TCP transport layer. The handshake that happens now over this active TCP connection follows WebSocket protocol and agree on following payload structure as JSON, XML, MQTT, etc. that both the browser and server can support via the Sec-WebSocket-Protocol Request and Response Header respectively. Once the handshake is complete, the client can push data to the server while the server too can push data to the client without waiting for the client to initiate any request. Thus a bi-directional flow of data is established over.
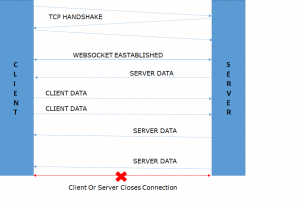
Figure 4: WebSockets
Ease of Implementation on client
- The modern browser provides a JavaScript class called WebSocket which abstracts a lot of overhead functionality for client
- The client simply has to instantiate the WebSocket class with server URL
- Note that though the HTTP in URL (ex: http://example.com) must be replaced with ws protocol (ex: ws://example.com)
- Similarly, https must be replaced with wss
- WebSocket class provides a connection closed callback when a connection is interrupted and hence the client can initialize a new WebSockets request
- WebSocket class provides a message received callback whenever the server pushes any data
- WebSocket class also provides a method to send data to the server
Ease of Implementation on Server
- On receiving an HTTP request from the client to upgrade the protocol, the server must provide HTTP 101 status code indicating the switch of the protocol to Web Socket
- The server also provides a base64 encoded SHA-1 hash generated value of secure WebSocket key provided by each client on handshake request via the Sec-Websocket-Accept response header
- The response header also includes the data format protocol via the Sec-Websocket-Protocol header
Critical Drawbacks
- Though there are libraries available like websockify which make it possible for the server running on a single port to support both HTTP and WebSocket protocol, it is generally preferred to have a separate server for WebSockets
- Since WebSockets don’t follow HTTP, browsers don’t provide multiplexing of requests to the server
- This implies that each WebSocket class instance from the browser will open a new connection to the server and hence connecting and reconnecting need to be maintained optimally by both the servers and the client
Below is a table summarising all the parameters:
| Polling | Long Polling | SSE | WebSockets | |
| Protocol | HTTP | HTTP | HTTP | HTTP Upgraded to WebSockets |
| Mechanism | Client Pull | Client Pull | Server Push | Server Push |
| Bi-directional | No | No | No | Yes |
| Ease of Implementation on Client | Easy via XMLHttpRequest | Easy via XMLHttpRequest | Manageable via EventSource Interface | Manageable via the WebSocket Interface |
| Browser support | All | All | Not supported in IE – can be overcome with Polyfill library | All |
| Automatic Reconnection | Inherent | Inherent | Yes | No |
| Ease of Implementation on Server | Easy via the traditional HTTP Request-Response Cycle | Logic of memorizing connection for a session needed | Standard HTTP endpoint with specific headers and a pool of client connections | Requires efforts and mostly need to set up a separate server |
| Secured Connection | HTTPS | HTTPS | HTTPS | WWS |
| Risk of Network Saturation | Yes | No | No | Since browser multiplexing not supported, need to optimize connection on both ends |
| Latency | Maximum | Acceptable | Minimal | Minimal |
| Issue of Caching | Yes, need appropriate Cache-Control headers | Yes, need appropriate Cache-Control headers | No | No |
Conclusion
Polling and Long Polling are client pull mechanism that adheres to the standard HTTP request-response protocol. Both are relatively easier to implement on the server and client. Yet both pose the threat of request throttling on client and server respectively. Latency is also measurable in both the implementations which is somewhat self-contrasting for the purpose of providing real-time data. Server-Sent Events and WebSockets seem to be better candidates in providing real-time data. If the data flow is unidirectional and only the server needs to provide updates, it is advised to use SSE which follows the HTTP protocol. But if the need is that client and server both need to provide real-time data to each other which can be the case in scenarios like a chat application, it is advised to go for WebSockets.








