


To develop and run various types of applications, Apache Flink is considered a great choice because of the variety of features it offers. Some of its prominent features are stream and batch processing support, advanced state management, event-time processing semantics, and consistency for the state. You can deploy Flink on multiple resource providers like YARN, Apache Mesos, and Kubernetes. Apache Flink is the new generation of Big Data Platform. It is also known as 4G for Big Data, Delivering high throughput and low latency. Since it supports both batch and stream processing, it enables users to analyze historical data and real-time data.
While developing or testing any application, we need a playground to experiment with our application. We need our playground to be independent, available at affordable prices, and easily preparable. Apache Flink supports creating a standalone cluster with few simple steps. It provides a friendly Web UI for monitoring the cluster and the jobs. In this blog, I will provide a brief overview of Apache Flink.
Then I will look into the prerequisites for setting up Apache Flink standalone cluster.
After that, I will set up a local standalone cluster. You will also learn how to start the cluster, submit an example WordCount job, and terminate the cluster finally.
What is Apache Flink?
Apache Flink is an open-source distributed computing framework for stateful computations over bounded and unbounded data streams. It is an actual stream processing framework that supports Java, Scala, and Python. Has a high-level Dataset API for batch application, DataStream API for processing continuous streams of data, Table API for running SQL queries on batch and streaming data. It also comprises Gelly for graph processing, FlinkML for machine learning application, and FlinkCEP for complex event processing that detects intricate event patterns in data streams.
Prerequisites for Apache Flink
Apache Flink is developed by leveraging Java and Scala. Therefore, it requires a compatible JVM environment to run the Flink applications. Some of the prerequisites for Apache Flink are as mentioned below:
| Language | Version |
| Java | Java 8/11 |
| Scala (only for writing driver programs in Scala) | Scala 2.11/2.12 |
Local Installation
In this section, we will do a local installation of the Apache Flink. Its local installation directory contains shell scripts, jar files, config files, binary files, etc. All these files are necessary to manage the cluster, monitor it, and run Flink applications.
First, we have to ensure that we have the correct Java 8/11 installation.
Then, we will download the Apache Flink distribution file from here,
We will extract the distribution file using the tar command
Now, visit Flink’s home directory to carry out the next steps:
Once, the local standalone cluster is installed, let’s start the cluster now.
Start the Cluster
The standalone cluster runs independently without interacting with the outside world. Once the cluster is up, jobs can be submitted to the cluster. The local Flink cluster quickly starts using a single script.
The Flink Web UI will be available on http://localhost:8081/.
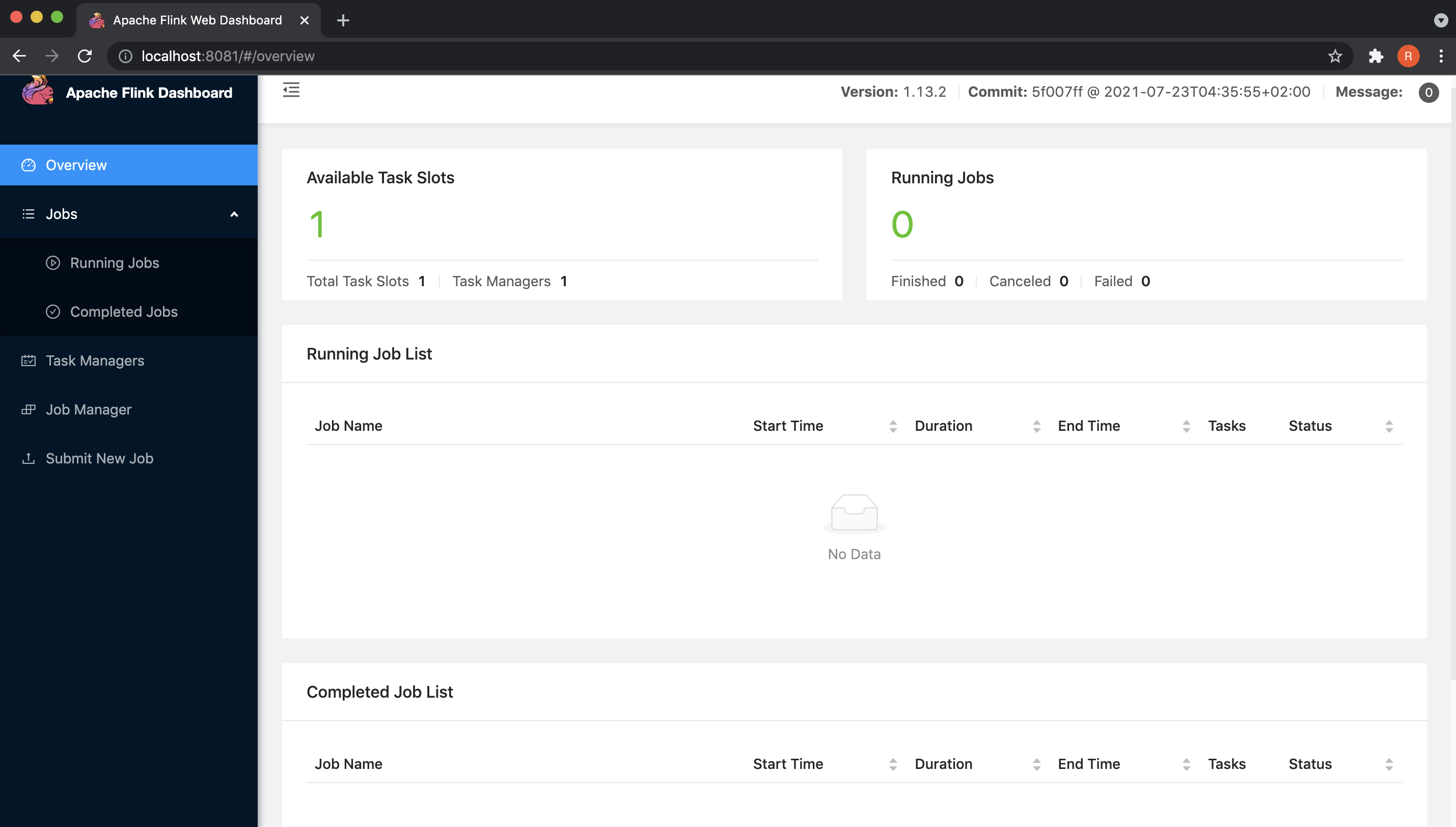
After successfully starting the cluster, the next step is to submit a job.
Submit a Job
A job is an application running in the cluster. The application is defined in a single file or a set of files known as a driver program. We write driver programs in Java or Scala, compiles them, and then build their jars. These jars are submitted in the running clusters through the command-line interface or the Flink Web UI.
The jar can have multiple class files. We can explicitly provide the name of the class file containing the driver program while submitting the jar, or it can be referred from the jar’s manifest file.
In this example, we will submit a WordCount job using the command line interface and using one of the existing example jars provided by Flink.
We can check the output of the job by running the tail command on the output log.

We can also monitor the running and completed jobs in the Flink Web UI.
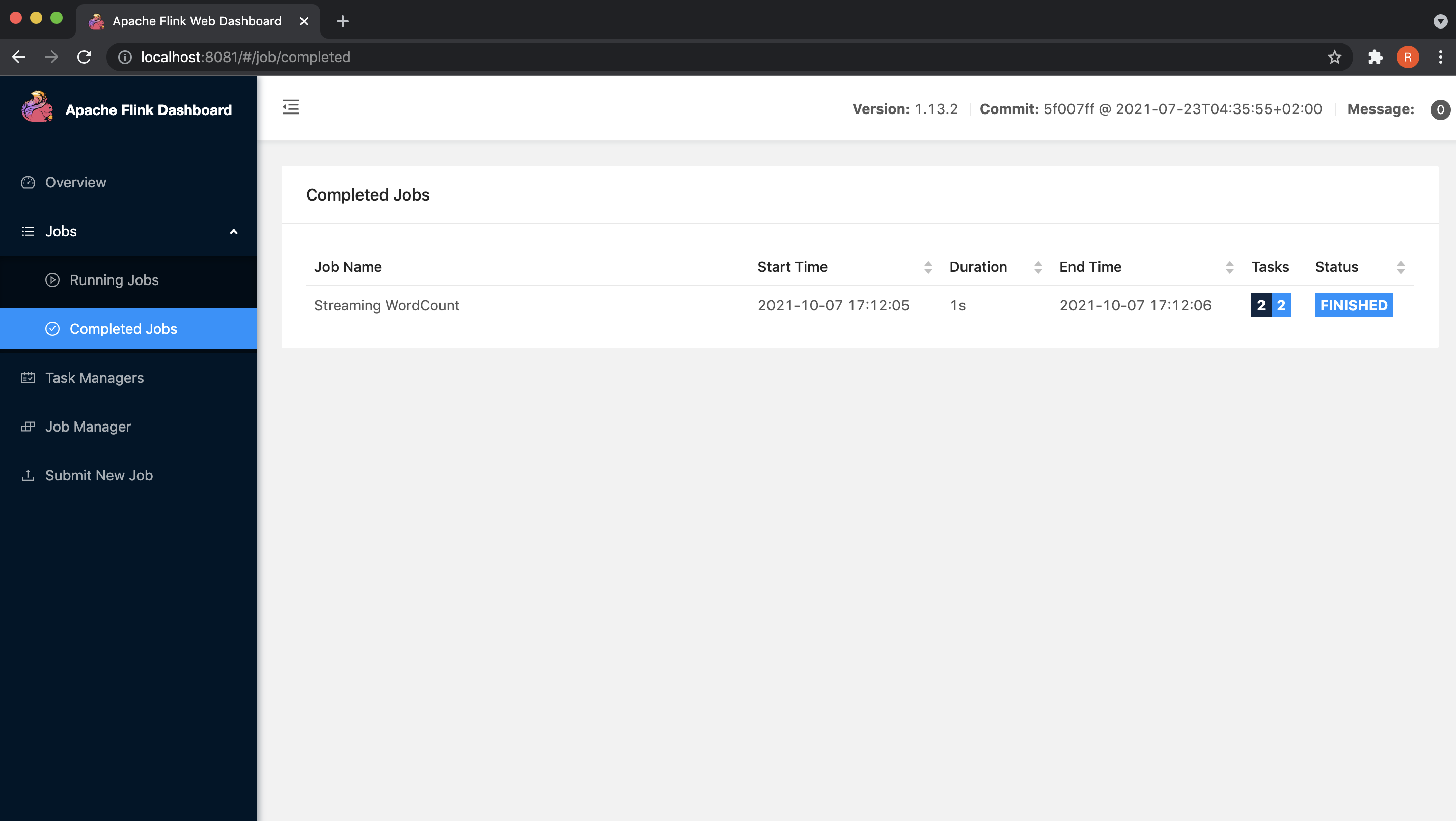
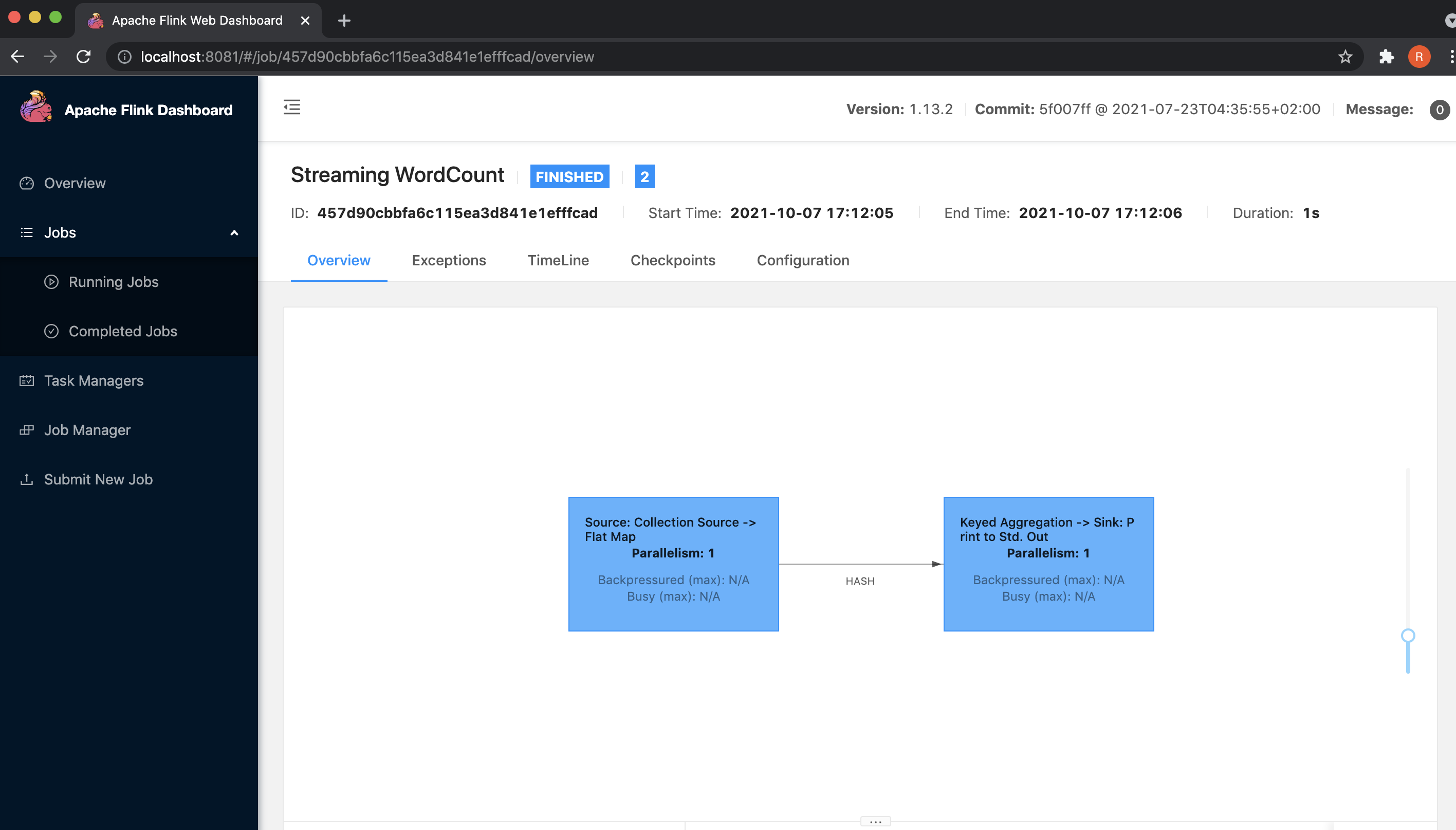
After carrying out these steps, we will now move towards the last step of terminating the cluster.
Stop the Cluster
When running the jobs on the cluster are finishes, stop the cluster and all running components by using a single script.
Conclusion
Apache Flink is a lot faster, more flexible, and versatile than other Big Data frameworks. A local setup will be an excellent start for learning Apache Flink. It also provides us with a nice environment to test our Flink applications before deploying them in production.
So, do try this method and share your experience with us. Happy coding!








